There are only two hard things in Computer Science: cache invalidation and naming things.
Phil Karlton
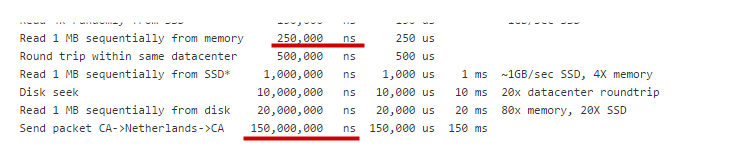
Caching is a common technique to improve the response time of a data source. A cache is a temporary storage for a most often acquired data. Caching is widely used in a proxying software such as Squid. The caching of network responses can provide a huge improvement to the response time. The latency of a network resource is much more greater than of a memory or a disk resource [Fig.1]. That’s why the caching is a “must-have” feature of network proxies.
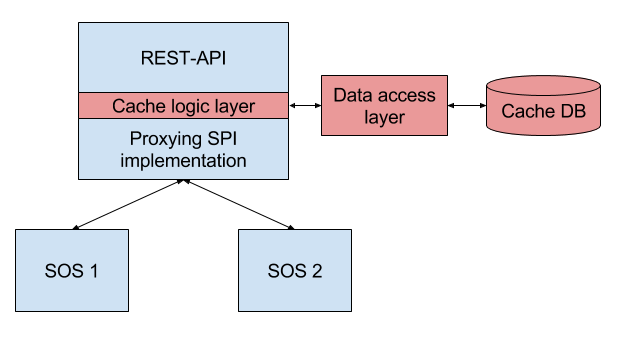
The goal of the project is to add caching capabilities to a Sensor Observation Service (SOS) Proxy service. A SOS Proxy implements the Series REST-API interface. The Series REST-API is a lightweight interface for querying time series data from the arbitrary backends. Implementations of the API’s Service Provider Interface (SPI) can then provide data via the Web interface. In the case of the Proxy, API requests are delegated to SOS backends. As these are 3rd party services, caching data is important to obtain more control over quality of service (QoS) requirements.
While the regular cache works with discreet chunks of data (HTTP-responses, files), the cache in the Series REST-API will work with time series data, so the logic of merging and storing such data must be implemented in the cache. The domain model of the Series REST-API layer must be taken into account while implementing the caching logic. The other distinction is the requirement to have an ability to use different caching databases.
The possible approach is to add an additional layer of caching logic to the REST-API project. The caching layer consists of logic and data access sublayers. The logic layer solves the problem of comparing stored and requested time series. The data access layer abstracts the underlying database and allows for the plug-in of different databases. The caching logic and data access layers can be implemented as a set of Spring beans.
The implementation process of the cache can be separated to three different tasks:
- Developing a logic layer
- Designing a data schema in a storage
- Integrating it into existing codebase.
The storage may be implemented with existing solutions like Infinispan, Redis, H2, or InfluxDB. The actual choice of databases depends on a subsequent research.
The quality of caching logic is a crucial point, because all data flows through it. Errors in caching logic can lead, not only to failures, but also to more subtle bugs such as corrupted data. I plan to ensure the correctness of caching logic by unit-tests and functional autotests. Unit tests are implemented with JUnit and Mockito. Functional tests can be done via Postman or REST-Assured and Wiremock.
Demonstration of caching capabilities requires several web services to be started. Deploying several web services is a hard task and it’ll be automated with the prepared Docker images. The Dockerfile for SOS Proxy and SOS will be created, as well as the instructions on how-to run it as a Docker image.
About me
My name is Anton Egorov. I’m a second year Master’s student at Moscow Technological University. My hobby is to messing up with a computers and to persuade them to do useful stuff. Eventually the hobby has become a something more and today I’m a backend developer. I’m excited that now I can spend time programming for a broad community and not just for my GitHub profile.
Leave a Reply