Introduction
The enviroCar SPARQL endpoint is a feature that enables the enviroCar data to be queried in RDF. This feature creates an open endpoint for crawlers and other bots and allows them to crawl the data and let the data be part of the LOD cloud. With the enviroCar server’s current architecture, it is possible to query the data by converting the entities on the fly into RDF when a particular kind of request is made. Please find a more detailed description about the project’s evolution on the SPARQL EndPoint wiki page.
Over the past few weeks, I’ve embarked on the task of moving the data from mongoDB (the database of choice for the enviroCar server) and cloning the entire database content to a raw data type, independent of database formats. My task also involved solving the problem of trying to remove the tight coupling of frameworks with the generation and retrieval of data. This would make more data interchanging processes more commonly known as ETL processes. This is a design for future implementation and can be found here.
Endpoint Repository and Proof Of Concept
I initially worked on a module independent of the enviroCar server which only dealt with the final stages of the endpoint. My mentor and I decided to use Apache Jena Fuseki . It comes reconfigured as a servlet running on a jetty web server. If the data is fed into Jena Fuseki, it takes care of the querying and storage procedures.
My repo https://github.com/gotodeepak1122/SparqlEndpoint puts in data from an RDF file and subsequently writes this data into Jena Fuseki. In order for the data to be fed in, Jena Fuseki must be started. This is similar to any database server. Once the module is run, the RDF data is in Jena Fuseki and can be queried later by restarting Jena Fuseki. If Jena Fuseki runs all the time within the enviroCar context, there is an interface for querying data. When made public, it creates an endpoint.
The next issue is to clone the enviroCar data and put that data into Jena Fuseki. If it is up and running, we have a functioning enviroCar EndPoint for Linked Open Data!
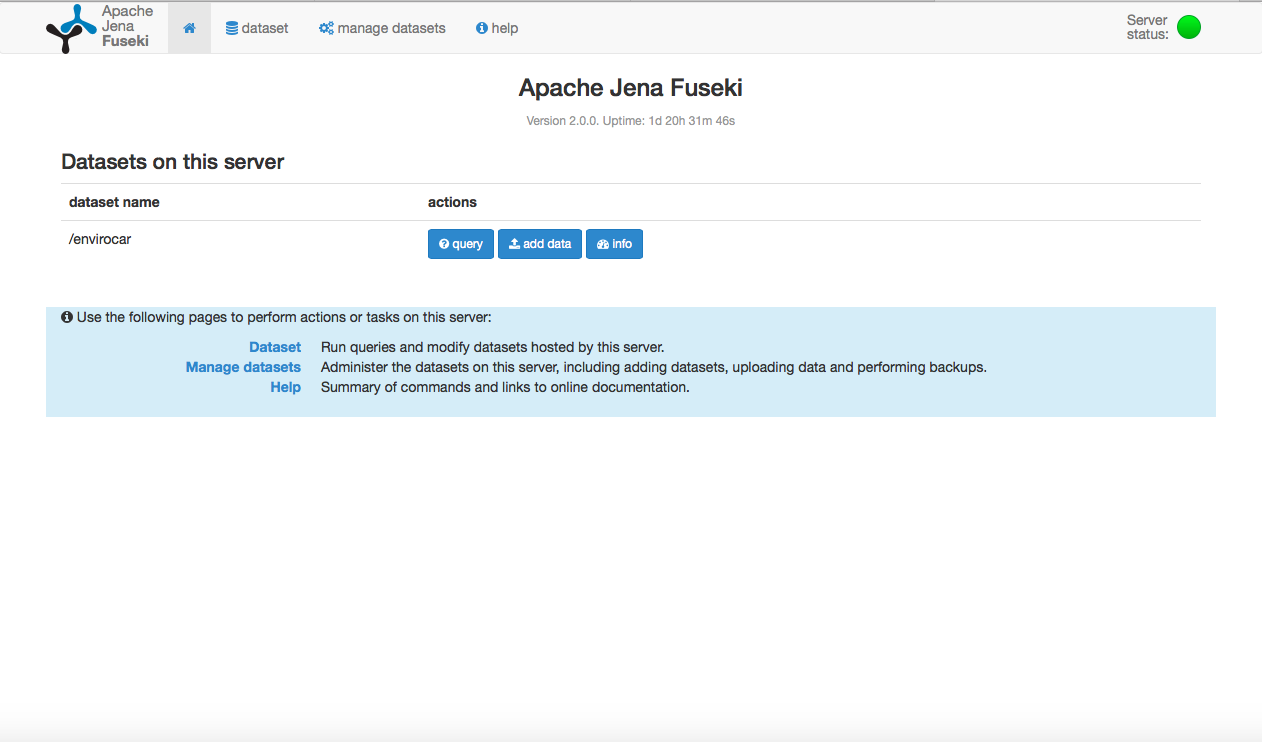
A screenshot of the Apache Jena Fuseki running with a sample dataset inserted through the ETL module
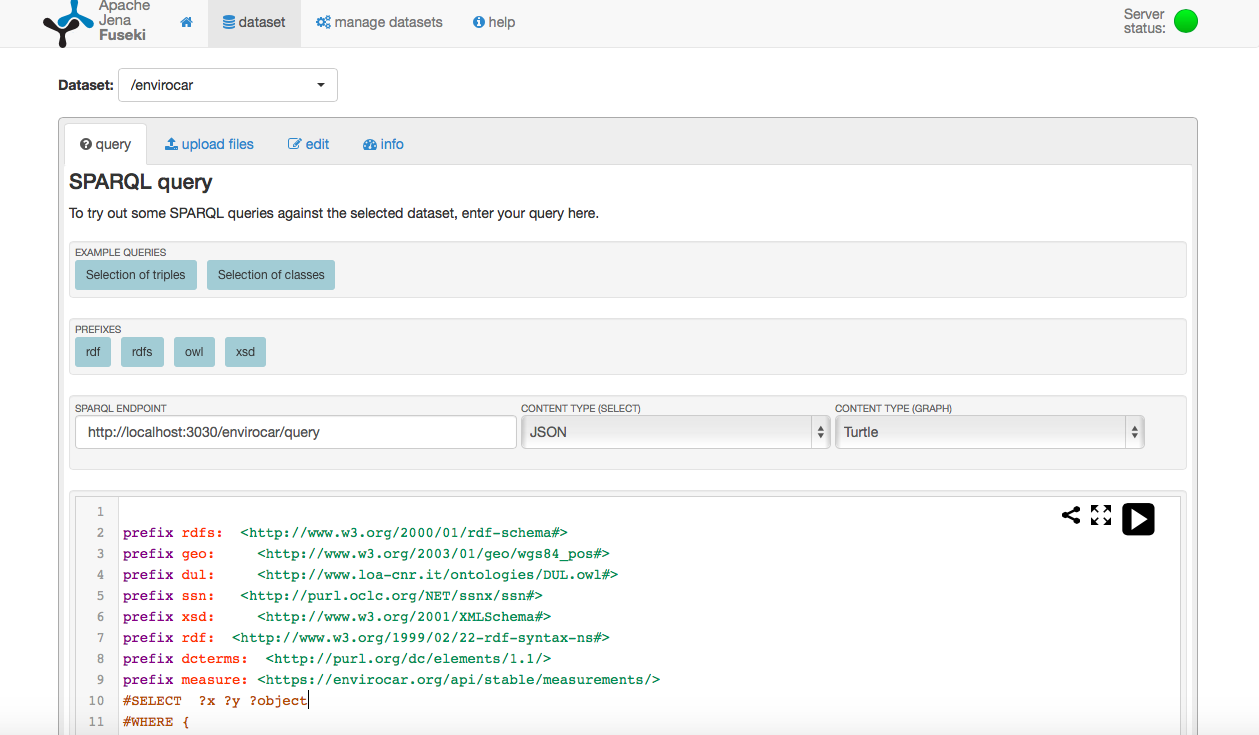
A screenshot of what the EndPoint’s query interface looks like with different options
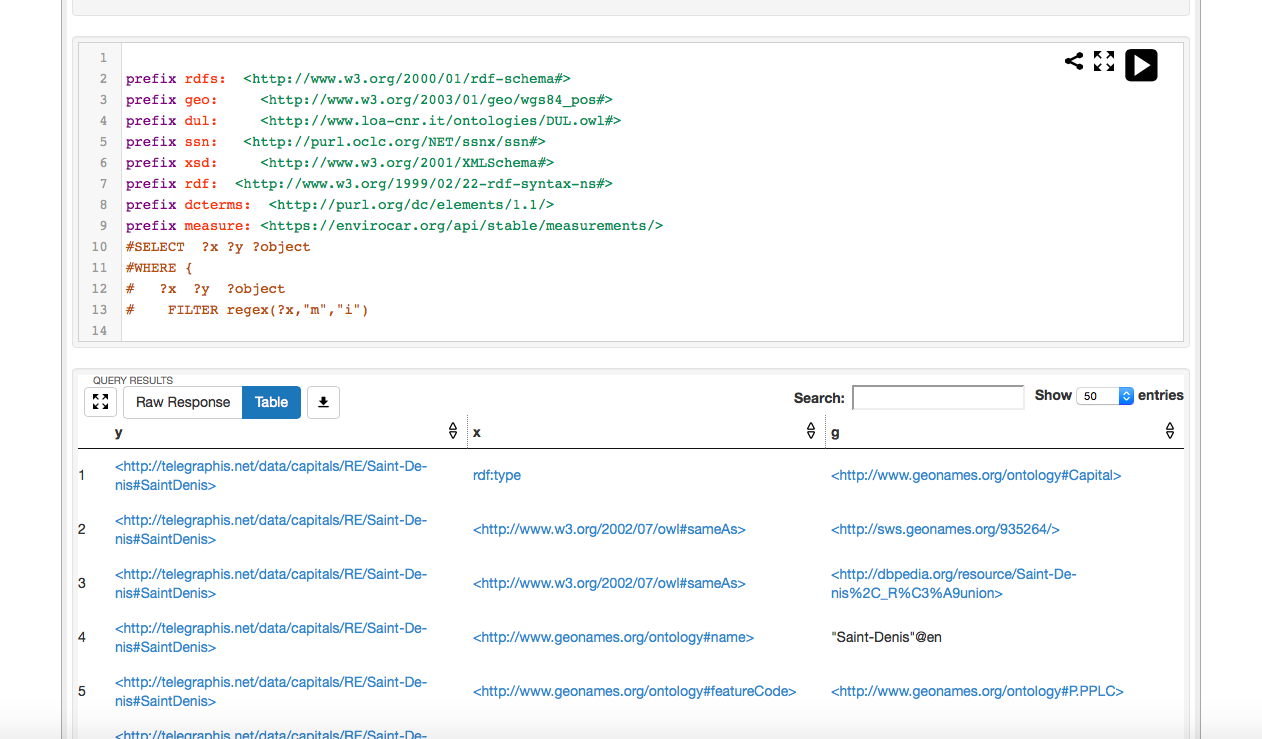
An example of an equivalent of SELECT * of sql in SPARQL to show all existing triples
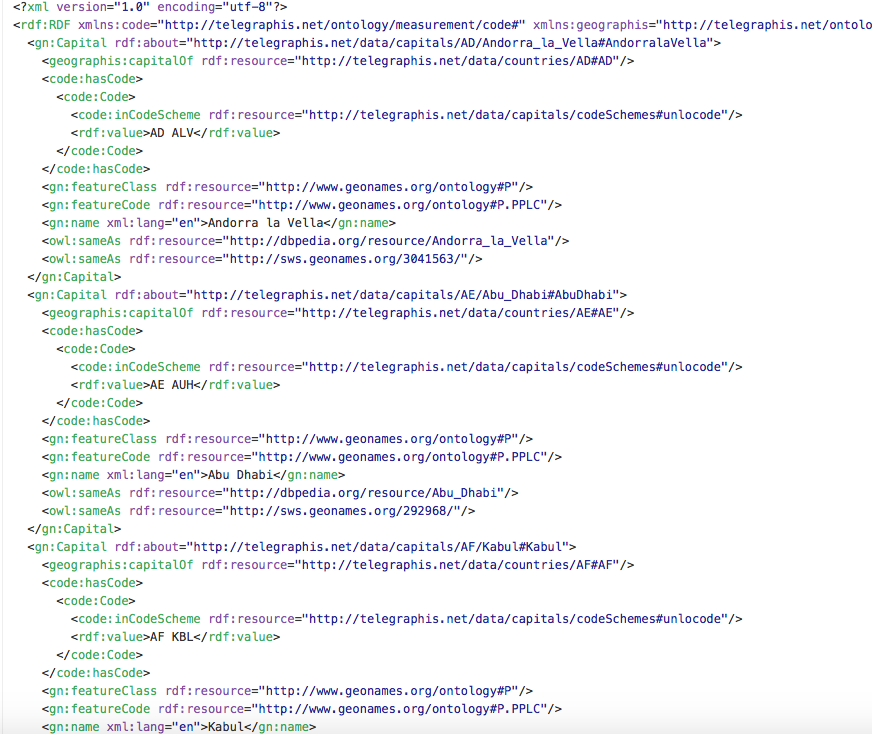
A screenshot of the RDF file previously inserted through the module into the datastore
ETL Module in the enviroCar Server
An ETL module in the enviroCar server is required because the data format in the database and the one required for the project are very different. Hence this process converts the data from the existing form into the one suitable for my project. The ETL module in the enviroCar server integrates all the running pieces required to integrate the data from MongoDB into a Jena Fuseki format.
The Architecture consists of three main modules:
- Cloner: loads the data from the source
- Dataset Dump: stores the data temporarily
- Loader: puts the data from the Dump into the target
This module combines to make the data accessible in a triple store and takes one more step towards making the information collected by the envirocar platform easier to analyse and use to perform studies .
Acknowledgement
I would like to thank all organization admins for their support during the process and timely updates and reminders. I would also like to complement Mr. Autermann for the very abstract and reusable enviroCar server code. This helped me implement raw data without having to model data from scratch. He was also very responsive to help. I would also like to thank my main mentor Mr. Carsten Kessler – who has been communicating with me everyday – for being excellent, supportive and understanding. Without his supervision and guidance, the progress and cohesiveness would not have been possible.
Future Work
- Identifying and implementing the linking possibilities of entities with each other and external sources.
- Converting the upload of data to Fuseki using SPARQL protocol or updates.
- Testing the cloner for the entire enviroCar dataset to catch bugs and mistakes, rectify them and make the module runnable over the entire enviroCar dataset.
Leave a Reply