Hello all,
I welcome you all to the introductory blog post on my Google Summer of Code‘s project that I will be working on over the next few weeks. Before I begin, a bit of an introduction about me 🙂
I am a graduate student at the University of Calgary (Yes, I get to see the Canadian Rockies from my window!). I am pursuing my Master’s degree in Geomatics Engineering and working towards revising and improving the Open Geospatial Consortium’s (OGC) SensorThings API standard for my thesis.
OGC SensorThings API
The SensorThings API is an international standard developed by the Open Geospatial Consortium (OGC) that aims to horizontally solve the semantic interoperability and vendor lock-in challenges within the IoT landscape. It defines a standard data model that can be used to define any sensing application and specifies a set of web based protocol bindings such as HTTP, MQTT and OData with it for retrieving the data collected by heterogeneous sensors.
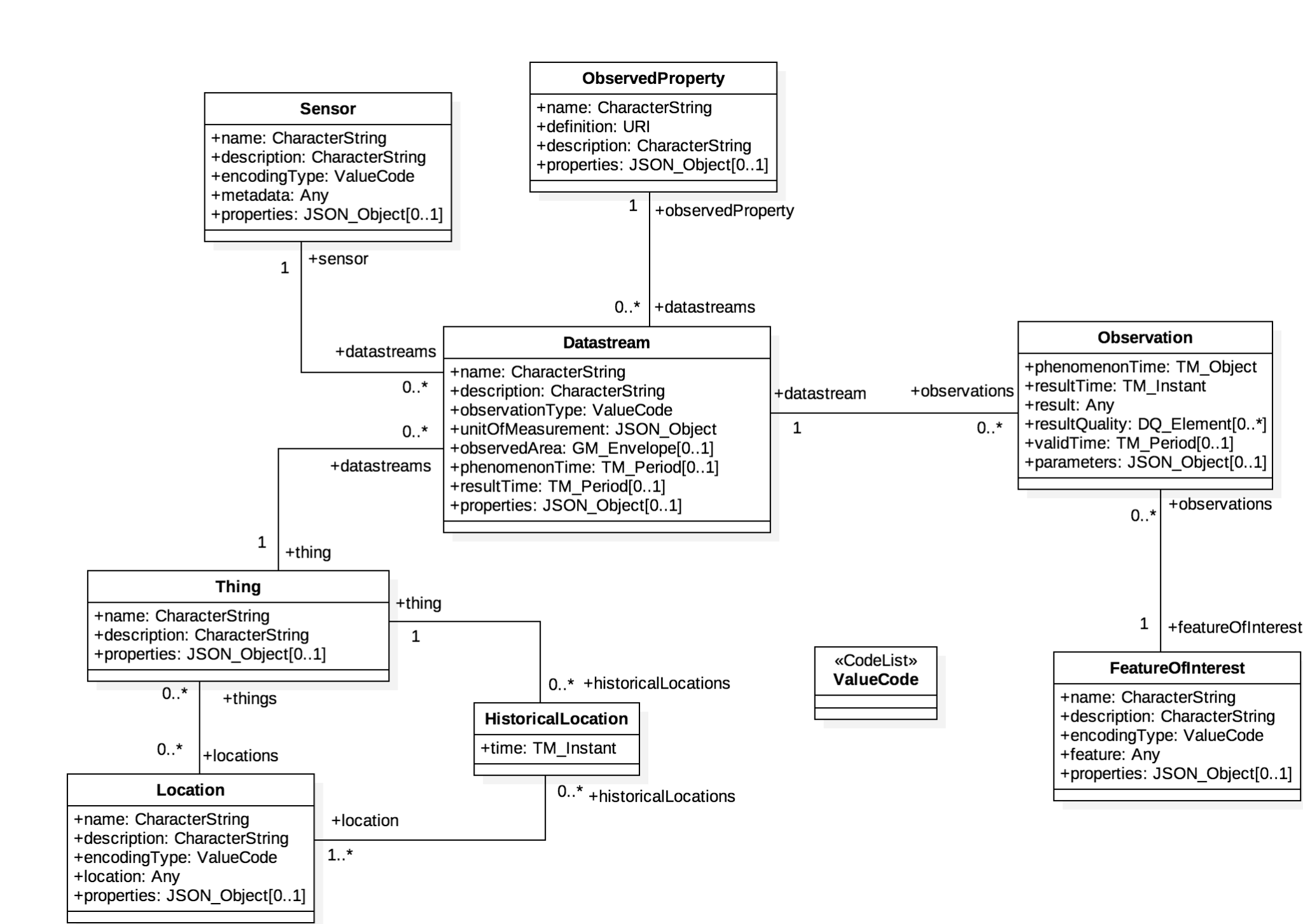
Project Proposal Background
As part of my research, I was evaluating the various ways in which the standard has been implemented and used by users and organizations to better understand its strengths and limitations. Many organizations that have leveraged the SensorThings API standard are national level environmental monitoring bodies that needed a lightweight, web-enabled and semantically interoperable technology to record and analyze large volumes of sensor data. Since we are talking about sensor monitoring networks across large geographical regions, the number of sensors pushing observation data every second would quickly overwhelm traditional database management systems. The French Geological Survey (BRGM) has recorded over 136 million sensor observations on their SensorThings API deployment, measured by 359 sensors in their monitoring network. While this is a public deployment, there could possibly be private deployments that have recorded a much higher volume of data. Hence, it becomes increasingly difficult to store and retrieve such large volumes of data using transactional database systems. The problem is exacerbated by the fact that (almost) all open source server implementations of the standard have only used Postgres/PostGIS as the data storage component for the incoming datastreams. GeoParquet, a new and interestingly relevant column oriented file format for storing geospatial tabular data in a cloud-native way, felt like a really great alternative to organize the ingested data. Some initial benchmarking tests revealed that if the data is sorted and partitioned spatially and temporally, running SQL queries on a large SensorThings API dataset using a distributed query engine could significantly enhance the query run-times (up to 3x-5x) as well as drastically reduce the storage costs (up to 10x). This is possible largely because of the predicate pushdown technique which prunes much of the irrelevant data based on the hierarchical metadata statistics stored alongside the data and the native compression model of Parquet format.
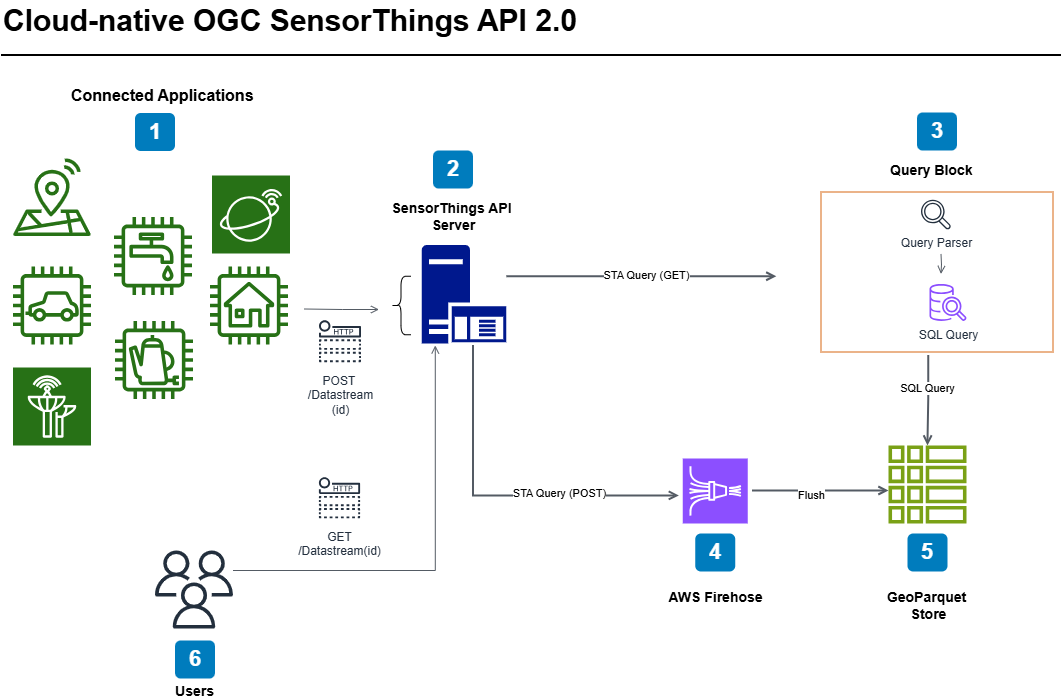
This is what led me to draft my own proposal. Since 52° North has its own open source implementation of the OGC SensorThings API, I was naturally inclined to reach out to Benjamin Pross and discussed my idea with him for GSoC ’24. The goal of my project is to implement a cloud native DAO layer for the SensorThings API using GeoParquet as the native file format.
Community Bonding Period
Initially, we were unsure which codebase to use for the development. We decided to use 52° North’s SensorThings API server implementation after a meeting with my mentor Benjamin. I also discussed an alternative design architecture with him using a data streaming platform (such as AWS Firehose) to aggregate the incoming datastreams. Since then, I have started ramping up on the Java based Spring framework and simultaneously started exploring the codebase. I have also set up my development environment. Since a major portion of my work will require the development of an alternative DAO layer, I am focusing particularly on the sta-data-provider-hibernate package of the codebase that has modules for parsing the OData queries as well as connecting to the database. I am looking forward to pushing some code in the package in the coming days.
On a closing note, I would like to thank Google, 52° North and my mentor Benjamin Pross for the wonderful opportunity to implement my research hypothesis and continued support.
Leave a Reply