Introduction
The aim of the OpenSensorSearch project is to provide a fast implementation of a sensor discovery server with the high performance of a Solr back-end. In addition, we are working on harvesting mechanisms for OpenSensorSearch to allow users to write harvesters for their own sensor data sources.
During this first term, I have had frequent contact with my mentors, twice a week on Monday and Friday. We stick to a Scrum-like methodology and rely heavily on test-driven development. The main considerations and tasks during the first half of the project runtime were:
- Testing and extending the existing 52°North Sensor Instance Registry (SIR) implementation: Since the project builds upon the SIR implementation, it must be carefully tested and extended for the OpenSensorSearch implementation.
- Providing fast indexing and retrieving: The metadata indexing shall use the data fields supported by Apache Solr for fast indexing and retrieving.
- Developing easy and open harvesting mechanisms: The harvesting mechanisms must be both easy and open to make it accessible to wide span of developers
SIR implementation
To make sure the SIR works as specified, we implemented a complete set of integration tests. They check all functionality of the current SIR implementation. The integration test covers all SIR operations, which helped us to identify two bugs which had to be fixed:
- The SirConfigurator that handled the server configuration was not installed properly and required a new handling mechanism.
- The HarvestService operation was not working as expected.
Metadata indexing
The most important part of the search engine implementation is the indexing of the metadata, thus an important stage of the process was just that. We decided to index all the fields that are required for a fast, high performance discovery of sensor, sensor data, and Sensor Web services. The following fields are indexed:
- id
- LongName
- ShortName
- Keywords
- dtstart : The valid time start.
- dtend
- location : a pair of comma seperated lng/lat values to specify the sensor’s location.
- Bounding Box center : since Solr doesn’t allow indexing of the bounding box, we indexed the box’s center to use it with spatial search .
- identification
- contacts
- classifiers
- inputs and ouputs
Please check the schema file for more information:
https://github.com/Moh-Yakoub/OpenSensorSearch/blob/master/52n-sir/src/main/resources/xml/SolrSchema.xml
We implemented complete unit and integration tests, as well as accessors, for each of these fields. Please check the package org.n52.sir.ds.solr for detailed information.
Performance Evaluation
To compare the Solr back-end with the PGSQL approach, we used the Apache JMeter (http://jmeter.apache.org). We ran three tests:
- Auto-complete performance test (to see how fast the auto-complete function works in the user interface).
- Query test using the Solr back-end.
- Query test using the PGSQL back-end.
The results were as follows:
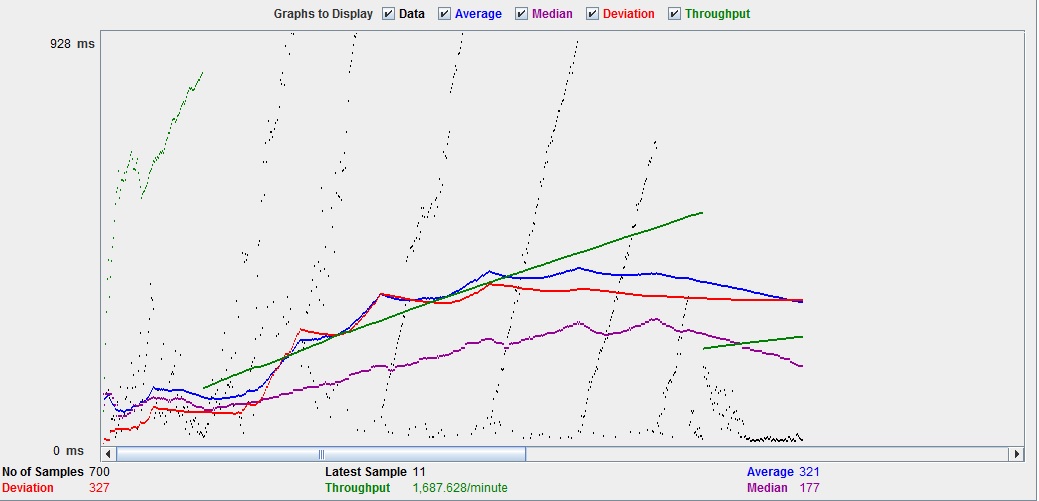
Fig. 1: The test performance of the auto-complete servlet that is used in content assistance for the OpenSensorSearch UI: This shows a throughput of 1687.628 query operations per minute.
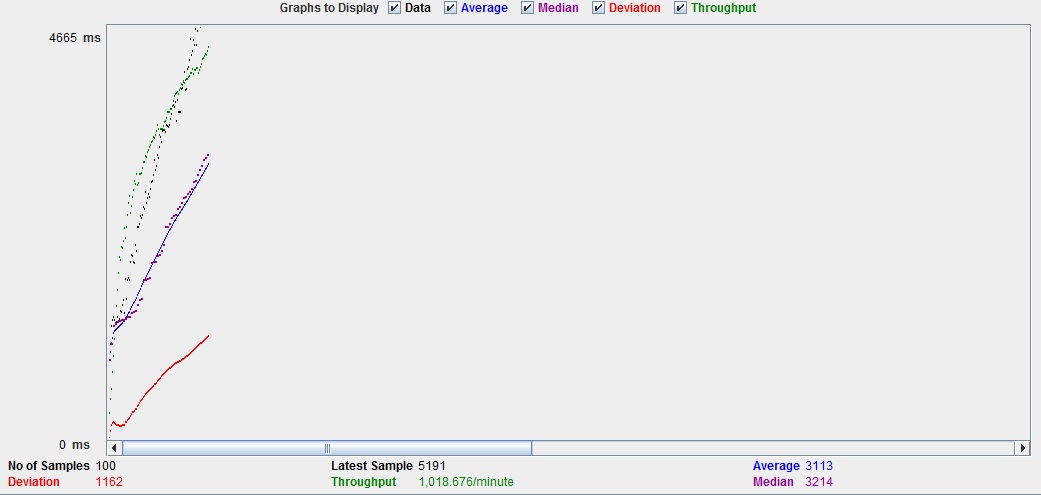
Fig. 2: Test against the PGSQL back-end (1000 dummy sensors using a dummy query): The result shows a throughput of 1018.676 query operations per minute
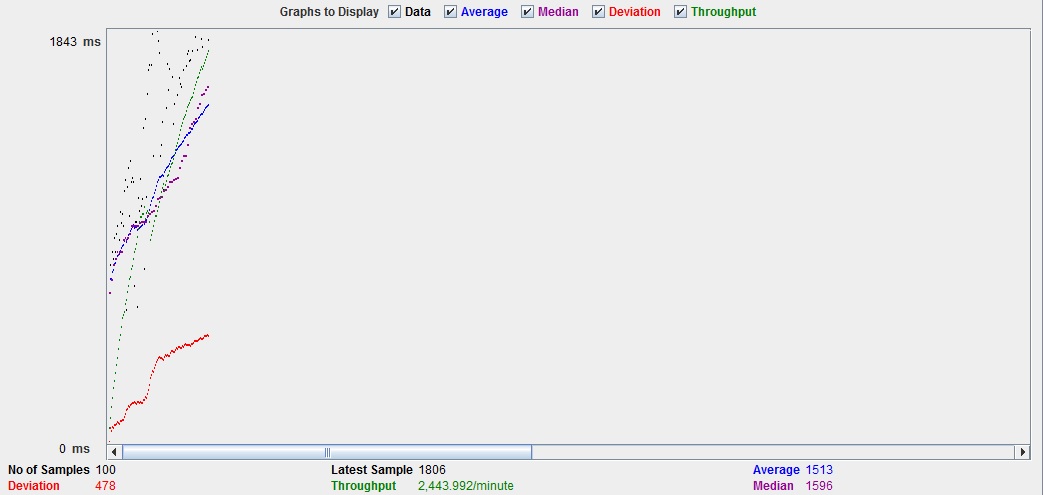
Fig. 3: Test against the Solr back-end (with the same 1000 dummy sensors and the same dummy query): Now we have 24443.992 query operations per minute. This is a really impressive improvement.
Query and OpenSearch specifications
The query for temporal and spatial search sticks to the OpenSearch specifications as found in
- Spatial search : http://www.opensearch.org/Specifications/OpenSearch/Extensions/Geo/1.0/Draft_2
- Temporal extension: http://www.opensearch.org/Specifications/OpenSearch/Extensions/Time/1.0/Draft_1
We ensured compliance by relying on unit and integration tests against the OpenSearch interface.
Content assisted queries
The UI of the OpenSensorSearch front-end allows content assisted formulation of queries based on all of the indexed fields in any order. This provides users with a much more comfortable experience. In addition, this component is fully quality assured through unit tests. The current results of the performance tests can be seen in figures 1 – 3.

Fig. 4: The content assistance functionality. In this example the query contains keywords , inputs and outputs.
Dummy test sensors
To test the back-end and its configuration and to execute performance testing, we used two mechanisms for dummy test generation. One was based on a template and one on completely random test sensors stored in the project resources. For more information you can consult the following classes:
- org.org.n52.sir.ds.solr.data.TemplateSensorTest
- org.org.n52.sir.ds.solr.data.JSONSensorParserTest
Bug fixes
We discovered the following bugs during the integration tests and the implementation process.
- Harvesting: Depending on the configuration, the original harvesting mechanism does not work as specified.
- InsertSensorInfo : It did not add sensors. However, this issue has been solved so that it successfully adds the sensors to both the Solr and PGSQL back-ends.
Tasks for the next weeks
- Work on the other big part of the project: the harvesting mechanism to allow developers to harvest their own sensors using their own scripts, for example JavaScript code.
- Extend support of formats for query results: OpenSensorSearch currently supports XML and JSON for query results. We also need to implement HTML and Feed results, as well as KML.
Stay tuned for more!
Leave a Reply