Introduction
There are a lot of reasons why it is useful to have your phone with you in the car and enviroCar encourages you to do so. At the same time, it’s a potentially dangerous distraction to use your phone while driving. Interacting with the enviroCar Android app while driving is a serious concern, as it may result in an accident. Hence, I would like to add voice command features to the app as part of Google Summer of Code 2022. Such a technical feature enables users to use the application’s functions through speaking instructions instead of the physical touch on the app. The voice command features will be implemented as part of a separate module that can be injected into the existing Android app.
Project Goals
1. Prepare the enviroCar App for voice command integration
The first goal for the project will be to prepare the enviroCar App for voice command integration. I will start with making a rough software design, which includes creating an UML (Unified Modeling Language) class diagram, a component diagram, and a speech recognition pipeline.
The UML class diagram will help to identify new required classes, which aim to handle tasks like command encoding/decoding as well as recognizing the user’s intention, and show how they will interact with the existing enviroCar App classes.
The component diagram will help us to represent the functionality and behavior of all the components that will be used.
And lastly, the speech recognition pipeline is a workflow diagram that will define what natural language understanding (NLU) parts (voice trigger, speech-to-text engine, intention recognition, etc) are necessary for the enviroCar App voice command features as shown above. An optimal workflow starts with triggering the speech request via a wake word (e.g. “hey enviroCar”, “listen”). When the app is ready for listening, voice commands from the user will be converted into text. The final steps include recognizing the intent of the user and performing an action that will occur in the enviroCar application (e.g. start recording, stop recording).
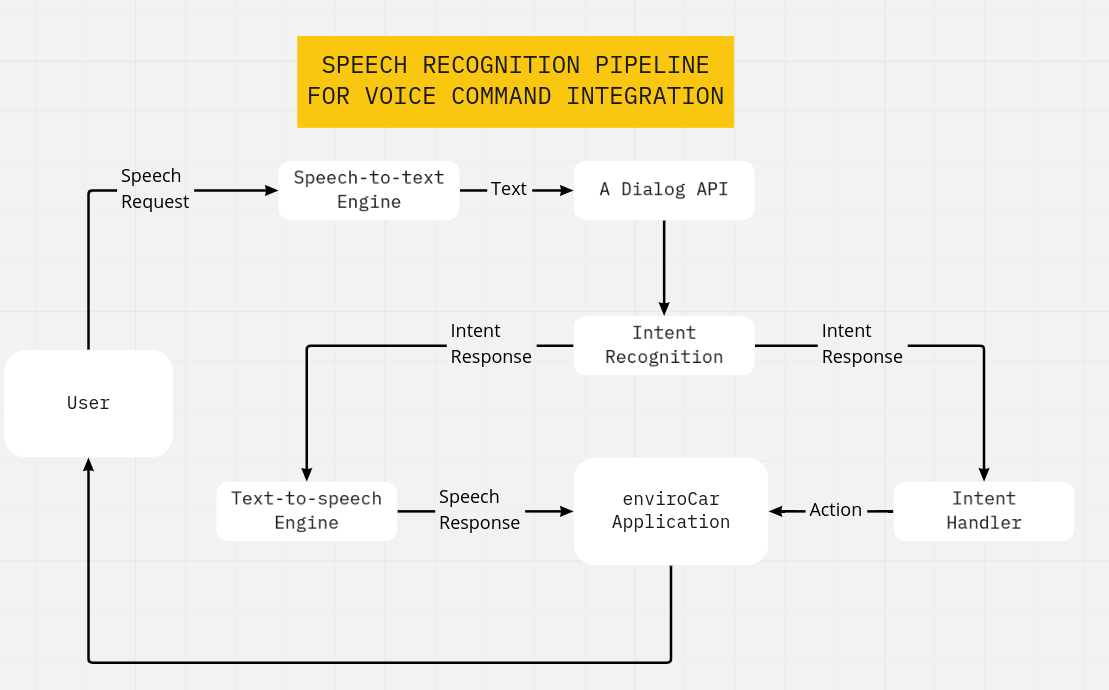
Once I have a rough idea of the design, I will start implementing the voice command functionality within a separate Gradle module. It can then be integrated into the existing enviroCar App module.
2. Recognize the user’s speech and translate it to plain text
One of the main tasks of the project will be to recognize the user’s speech and translate it into plain text. The user’s speech can be in different languages, such as German and English. I will start with the English language and once proper testing is done I will also integrate a German model. I also plan to add voice triggers similar to google assistance, which is triggered after saying ‘ok google’.
There are multiple reasons to favor a voice trigger over letting the user tap a button to trigger the voice recognition. The most crucial concern is that tapping on the screen while driving is a dangerous distraction as it may result in an accident. A voice trigger feature will help to reduce this concern and make this project production-ready!
We will use the AimyBox library throughout the project. It provides many out-of-the-box solutions for many of our tasks. I will get started with the voice-trigger part by adding a prebuilt language model provided by vosk-api. Once done with that, I will implement the recognition of the user’s speech and translate it to plain text using GooglePlatformSpeechToText provided by Google Play Services, which exists on most Android phones.
While implementing is a small part of this, testing is the bigger part. I will perform heavy testing on the model for voice triggers and document the bugs/unknown errors that might occur in the process in order to assess the limits of the voice trigger feature.
3. Recognizing the user’s intent via NLP/NLU
After transforming the user’s speech to plain text the third goal will be to use natural language processing/ natural language understanding (NLP/NLU) for recognizing the user’s intent and performing an appropriate action in the enviroCar App. The actions can be, e.g. switching the view, start recording, etc. Currently, the plan is to use Rasa Open Source for the NLP/NLU part and create a robust model to recognize the action. For this purpose, a backend server will host the Rasa components, which can be seamlessly integrated within Aimybox.
4. Testing/ Bug fixing
The final goal is to sweep for bugs on the entire codebase. This will include more testing, evaluating, and fine-tuning all the changes made thus far. In an early version, voice command feature will be implemented for dedicated actions on selected views. For instance, starting and stopping track recording via voice command would be a meaningful kickoff. Later, I will try to add voice command features for the remaining screens based on discussions with mentors and the enviroCar community.
About me
I am Dhiraj Chauhan, a second-year CS student based in Mumbai, India. I am passionate about technology and new ideas. I love working on Android. I enjoy using my skills to contribute to the exciting technological advances that happen every day via open source. I have been interested in software development since my first year and I have been exploring this domain since then. I like to listen to music while working for hours. I love interacting with folks and learning from them. This will be my first Google Summer of Code and I am super excited to work under the guidance and mentorship of Mr. Sebastian Drost, Mr. Benjamin Pross, and Mr. Sai Karthikeya.
These are my profiles: Twitter LinkedIn
Leave a Reply