Introduction
With only a few days left, the enviroCar SPARQL endpoint comes closer than ever to becoming reality. Much work and research has been put into an immensely important segment of the 52°North enviroCar project – the data. This project involves all kinds of data from standard relational to semi-structured to geo-spatial, which makes it both versatile and extendible. In a nutshell, we extract enviroCar’s data from its database form, convert it to the Linked Data format, store it in a triple store and serve it to the world as an Endpoint. Have a look at how different data looks when represented in different formats!
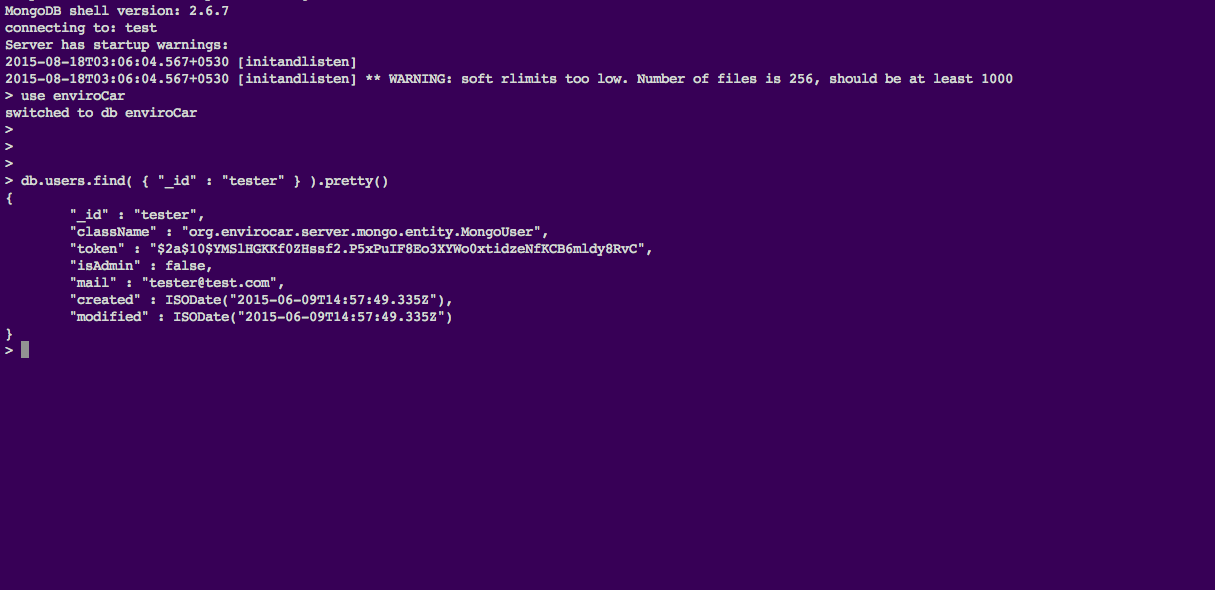
What a user named “Tester” looks like from a sample enviroCar database.
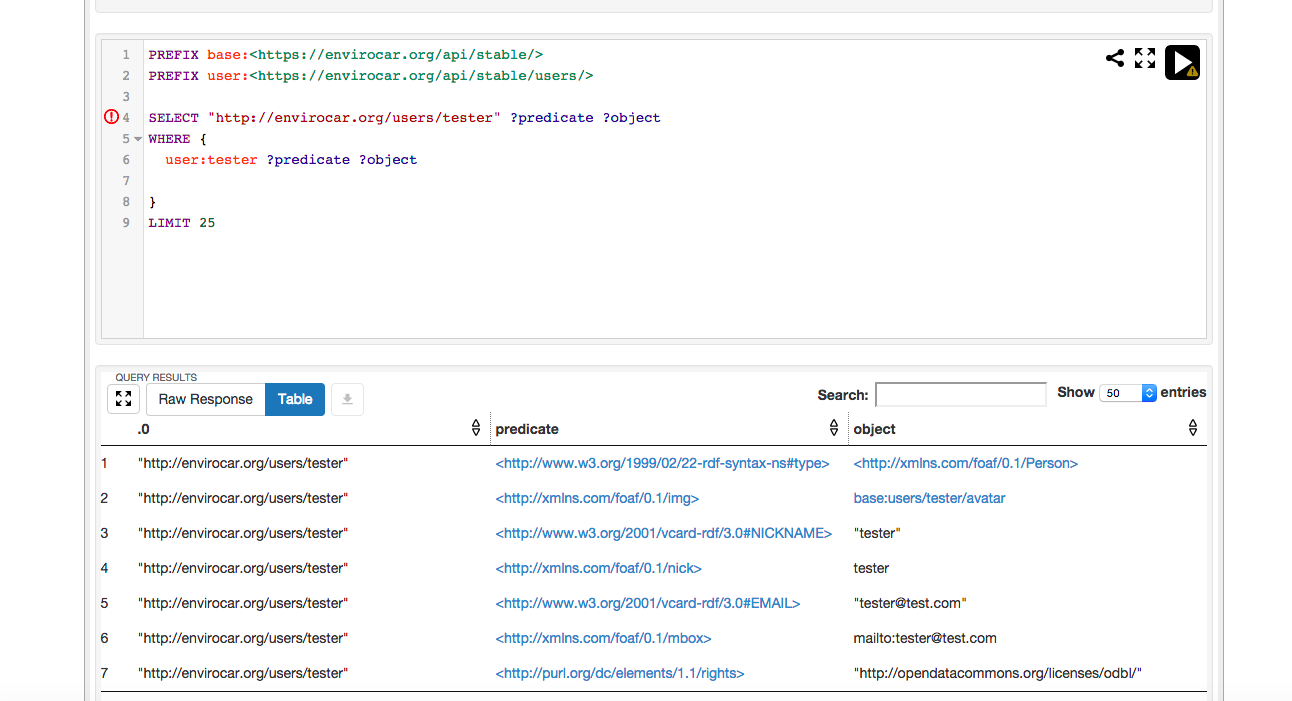
What the same user looks like in Linked Data !
Key Uses and Importance of this Project
This project is massively important and comes with numerous uses and benefits. It is important to understand why one needs to convert the data into another form and see it as LOD .
- It makes the enviroCar data more connected to and consistent with datasets in the outside world. Suppose a user of OSM is using geographic location. Linking this geographic location to enviroCar data will provide the user with additional information about traffic data and estimates of pollution at his/her (or given) location!
- It provides interchangeability and flexibility to the data, from which softwares can modify to their specific need.
- It makes collecting data from the web for analysis projects much easier. This is a huge boost for data scrapers and developers who have to normalize data from different sources. For example, suppose we are crawling through data and hit upon an entity described as “BMW”. If it only is a name, the computer has no way of finding out more information about the entity and gets stuck. If it is represented as a URI, we can find more information about its entity description and delve further into its part, properties and so on.
The Journey so far
When we started out, my summer of code Mentor and I discussed the project and planned three phases.
- Pull the data from MongoDB, convert it and store it into the other database.
- Make sure both databases are in sync with each other, so that when additional tracks get created and stored, they should get transferred to the other data store.
- Deploy a running endpoint responding to queries.
During the thirteen weeks, the following three phases actually happened.
- Extract the data into RDF dumps and upload it to a SPARQL server.
- Prevent hackers and unauthorized users from adding data to our Fuseki server.
- Implement autolinking of Open Data with other data sets, for e.g., linking city segment data with LinkedGeodata‘s dataset.
Hence the path deviated from the original one a fair bit. The goals were adjusted in a SCRUM style. Throughout the journey we have gained immense knowledge about architecting such a system, what are the challenges for a particular outcome and which advantages and disadvantages do the existing packages have.
- We discovered that Apache Jena Fuseki doesn’t secure applications the way it mentions, hence we have shifted to a method of sitting behind a reverse proxy, as advised by our mentor.
- In Christian Autermann‘s enviroCar server design, an entity, such as User, is an interface rather than a base class in the enviroCar code. This provides more flexibility to implement structures for data dumps.
The journey ahead
Thinking about a system for a long time gave me the opportunity to gain insights on the system we are trying to build and how it would develop in the future. Also it will help users to build new exciting features and applications around the project
Features like in built configurations for SPARQL servers , option to switch between on the fly updates and RDF dumps and full fledged automatic data linking are features that come up first and not far away from implementation
Summary
It’s been a long thirteen weeks with amazing learning and knowledge gained. I have to give credit to my Mentor Mr.Carsten Kessler for being a fantastic mentor and helping me out in the world of Linked Data and Spatial Semantics. Also, I would like to thank Daniel for his well planned use of Trello and constantly watching over and helping out throughout the course of the summer. There are some very talented people at 52°North and fantastic projects. I am glad I found this community. It’s come to an end all to soon and I have learned many lessons. A heartfelt thanks to all!
The key resources for the project:
Do you have a public sparql endpoint for the enviroCar opendata platform?