This week, we will have one blog post by each of this year’s Google Summer of Code students presenting their project and themselves. After Khalid, Patrick and Jinlong it is now Mohammad’s turn!
The sensor web is a broad concept about making sensor data available online. There is no such thing as “the” sensor web, but several systems for different purposes. This makes it really hard to discover sensors and their data. Therefore, I will implement the Open Sensor Search (OSS) idea for the Google Summer of Code 2013 (see wiki page). Based on the exisitng Sensor Instance Registry (SIR), we will work on a system using a fast and probably distributed search engine. The system architecture will be able to apply a harvest mechanism for sensor sites like Xively and Thinkspeak, but also OGC SWE services, and allow the users to harvest their own sensors using a comfortable user interface. Existing SIR features, such as the POX and KVP bindings, as well as the OpenSearch interface will be ported to Open Sensor Search.
The idea is to enhance the current implementation and allow more sophisticated actions like the ability to log in and harvest one’s own sensors using user-developed scripts in multiple languages (namely Javascript and Scala). Users will be able to upload their sensor metadata or let the open sensor search engine harvest the data for them. To make the search faster, we plan to use a high performance search engine like ElasticSearch or Apache Solr.
Our hope is to provide a useful service to the sensor web community with a fast search engine for sensors. As a first step, we are now working on improving the code quality (adding missing tests, doing proper integration testing) to achieve a reliable code base that can be extended easily for further implementations – the code is already on GitHub!
There are many challenges to this project:
- There’s an existing implementation (“legacy code”) that we work on, enhance and modify. The code needs to include proper integration and unit testing.
- The choice of the proper search engine must be made wisely, because an important aspect of this project is to have the user receive results faster.
- Our solution for harvesting one’s own sensors must be both generic – to allow users using multiple languages to be able to harvest their own sensors – and fast and have high performance.
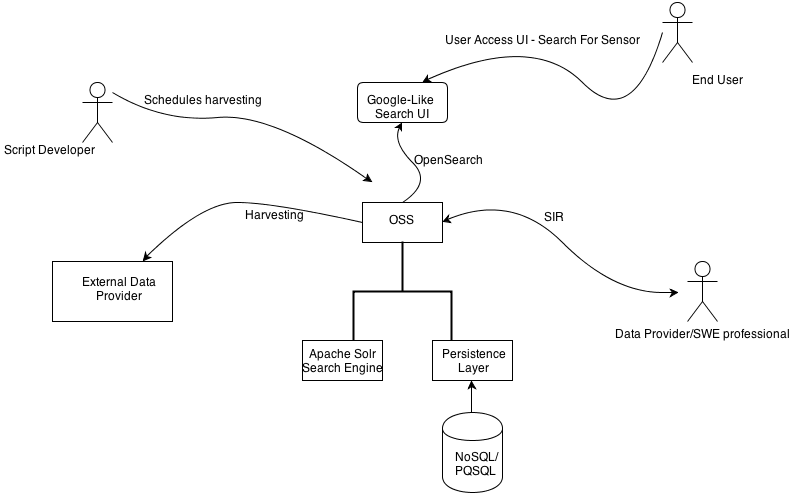
As shown in the figure, the OSS builds upon a persistence layer and a search engine component for fast spatial and thematic indexing. It provides an OpenSearch and a SIR interface to allow harvesting and description insertion into the back-end. The persistence of sensor data goes into a persistence layer, either NoSQL or a relational database, in addition to the indexing in Apache Solr engine. Both the search engine and the persistence layer can be extended to the cloud later and be distributed easily. We want to add a Google-like search UI on the top of the OSS . Users can also log-in, ask their data to be harvested, and manage sensor metadata, as well as their harvesting scripts.
About me
I’m Mohammad Yakoub, a premasters students studying computer engineering. I’m mostly interested in software engineering and have gained good experience in developing both web applications and mobile applications. The language I like to use most is Java.
I was interested in this project for many reasons: because it’s aimed at enhancing the performance and speed of this system, Also because I’m generally interested in working with GIS systems. It is always challenging to work on the top of an existing implementation!
You can find more information about my code at the public Github account.
Leave a Reply