The aim of the OpenSensorSearch project is to provide an implementation of a sensor discovery server with the high performance of a Solr back-end to give users results fast. In addition, we are working on harvesting mechanisms for OpenSensorSearch (OSS) to allow users and developers to write harvesters for their own sensor data sources.
In the previous blog post, we discussed the work done in the first few weeks related to the database back-end and how we used Apache Solr for indexing and fast searching. Today we present the work done in the second half of the project. It focussed on harvesting metadata from other sources and the user interface. I mainly discuss
- Javascript harvesting mechanism,
- “harvest callback” technique,
- user interface implementation with Spring MVC and
- general technical details.
Javascript Harvesting
We use Mozilla Rhino, a Javascript execution engine, to allow script authors to submit their own harvesting scripts to add sensor instances to the OSS database. With their own script, they can harvest any data source without us knowing the format or location of the data. A script can be submitted to OSS using a restful web service, which allows both submission and scheduling of scripts. Internally we use a quartz scheduler for script execution. The following example script harvests a ThingSpeak feed. It uses a couple of Java classes to insert the information to OSS. These classes can be strictly controlled to form a “sandbox” for script developers. Also note that we created a simple HTTPRequest class so that users can query arbitrary severs.
A simple script harvesting a feed from ThingSpeak.com can be found here. More examples can be found in the GitHub repository referenced at the bottom of this page.
“Harvest Callback”
The existing harvesting mechanisms (Javascript, and OGC SWE) are heavily language dependent or use a complex data model and interface. For example, in week seven we used many libraries and third party components to allow developers to harvest their own sensors using Javascript. While successful, this solution needs to be implemented for each language to make it accessible to a wide range of developers with different programming skills. Therefore, we want to provide an alternative, namely a restful mechanism which relies on a simple service interface definition. A user that wants to provide data to OSS can then implement this simple interface on top of his own database.
The full mechanism is outlined in the following diagram:
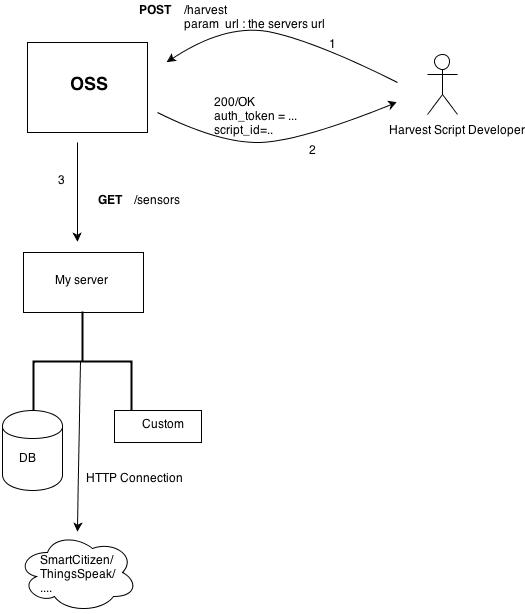
A web API allows the submission and scheduling of remote servers supporting this method. For detailed information check the wiki. The mechanism was implemented and tested using both integration tests and unit tests using frameworks like wiremock and mockito.
New User Interface
A whole new Spring MVC web application was implemented using bootstrap for layout and styling. It features login/registration of users, and users can schedule and submit their harvesting scripts or harvest callback URLs. The start page was enhanced with the autocomplete search based on the Solr back-end. On top of that, the new web service APIs are documented for developers with new HTML documentation pages.
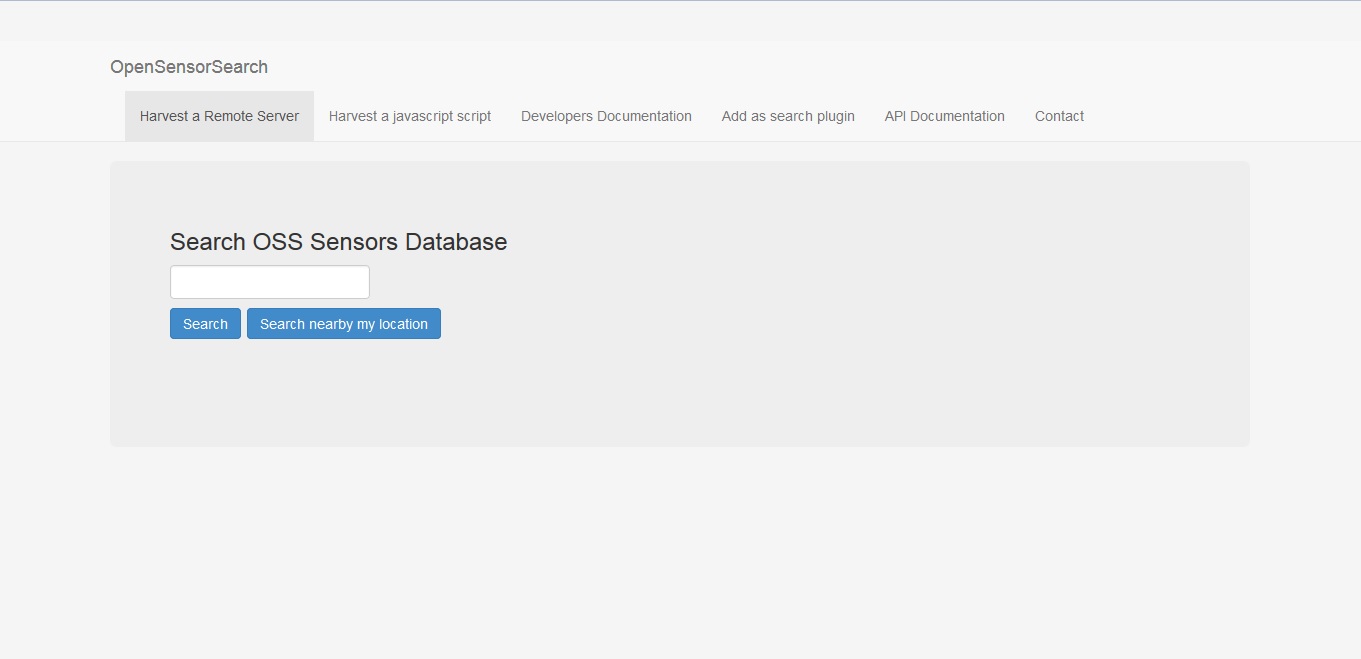
The main interface
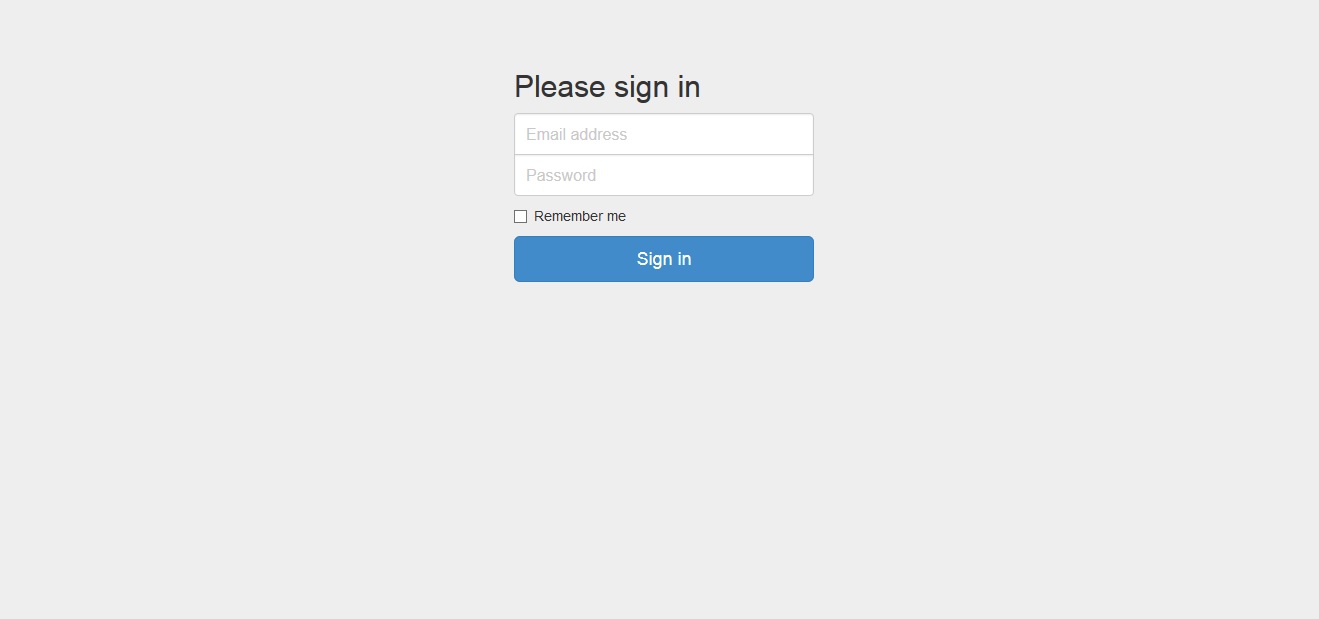
Sign in for script submission
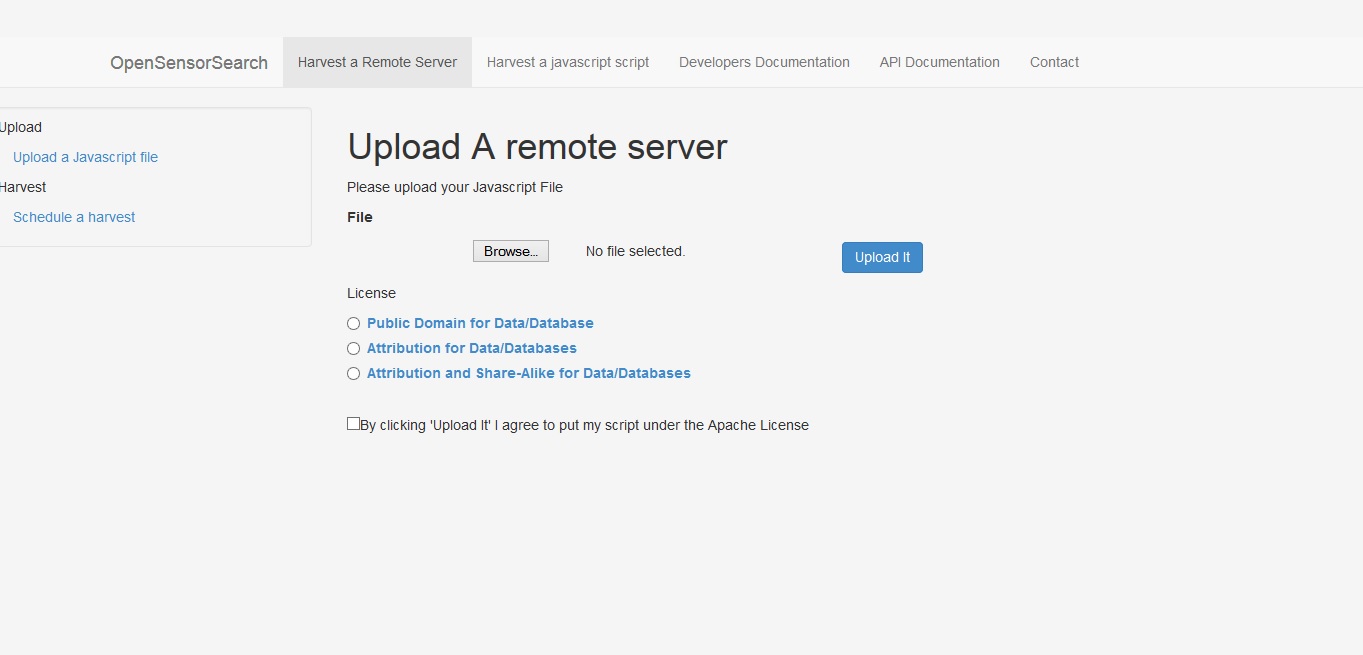
Uploading a Javascript file for harvesting
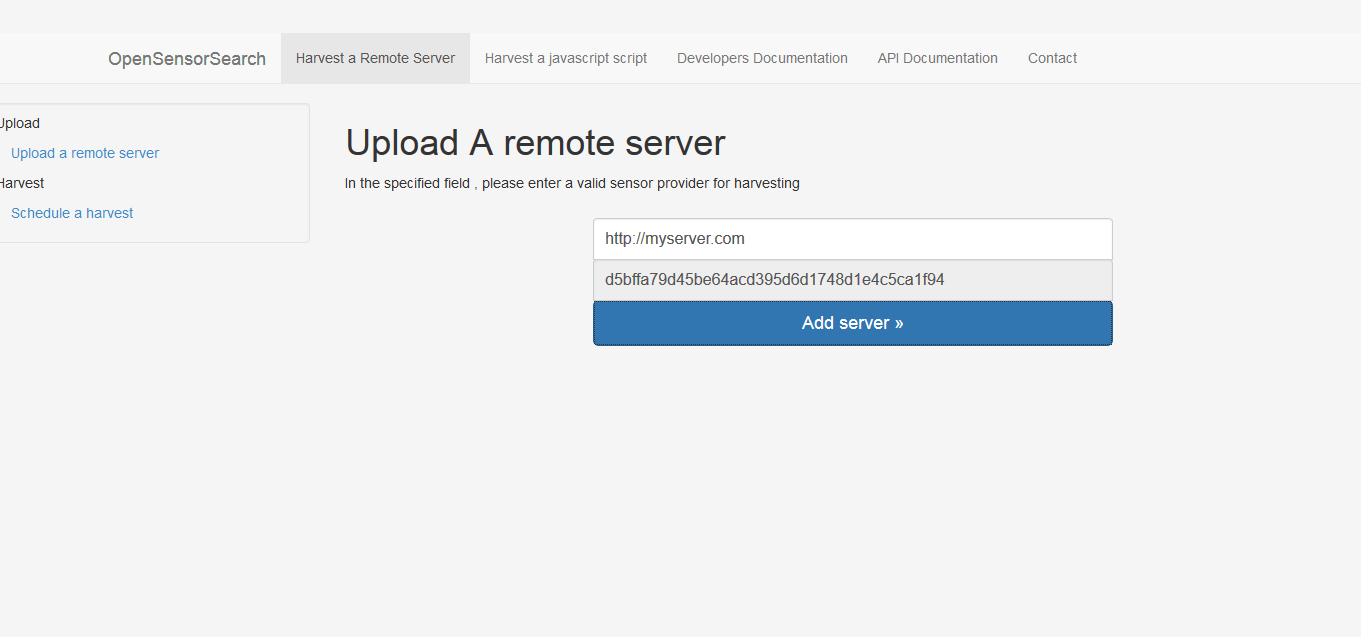
Harvest callback with auth_token returned
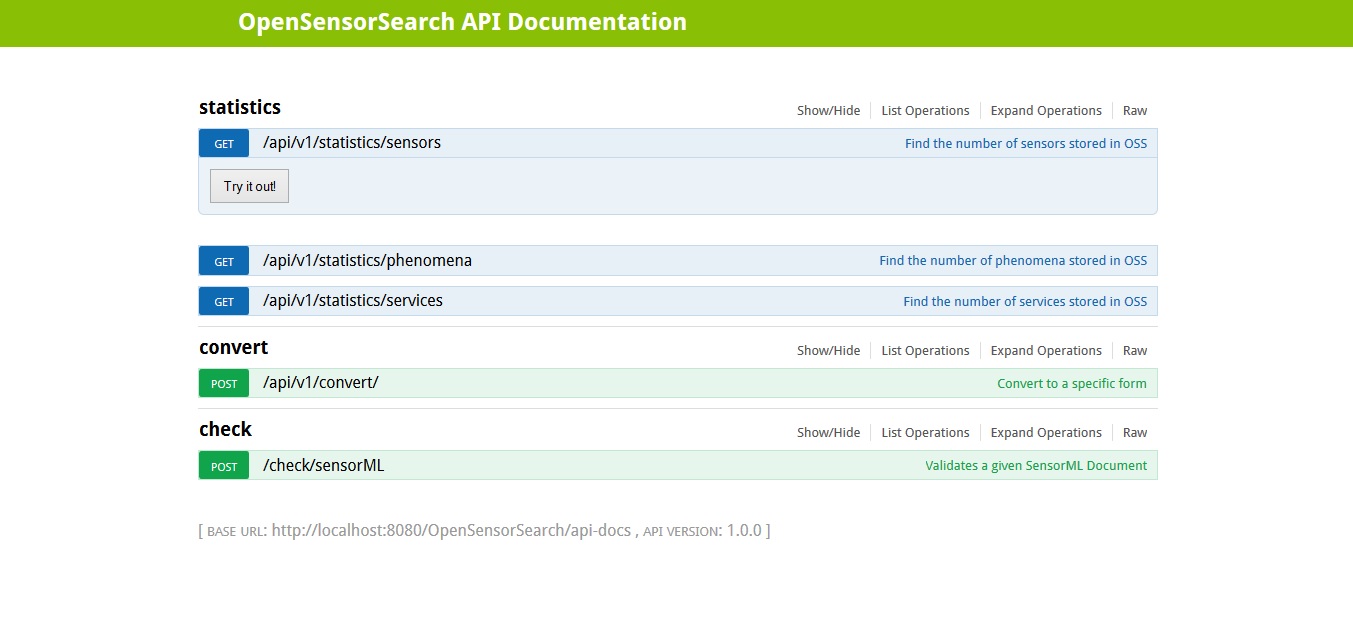
Developers API developed using Swagger UI
Screenshots of testing the UI on major browsers can be found at https://wiki.52north.org/bin/view/SensorWeb/OpenSensorSearchResponsiveUI.
Technical Details and Future Tasks
- Because we take integration tests seriously, we must admit that some weren’t written very well and some were missed, so we added all of those for reference and future use in our backlog system which uses easybacklog.com.
- As indicated in the previous blog post, the results were not decisive as to whether SOLR results were better than PGSQL or not, so we restrict it to autocomplete for now and wait for real data sensors for better testing.
- All of the app with it’s API and OSS-UI relied on DAO and pure SQL for query implementation. This got very complicated as the size of the project increased. So I think that a shift to an ORM tool like Hibernate would improve the project considerably.
- I think the data structures that are used need some working, i.e. we should implement a whole new classes of data structures to be used by script authors.
Summary
It was nice working on OpenSensorSearch even though it was tough at some times. To me, the most annoying things about it were the cumbersome configuration and sticking to a set of standards – that we have to – that tends to complicate things. For next summer, I would encourage students to work on this project and extend it, enhance it’s back-end and test it thoroughly, change the database access to use Hibernate and maybe extend the UI to allow more user levels and more capabilities.
Concerning my goals, I was able to achieve most of what I intended to do. I was delayed a bit by the time required to understand the system and it’s standards. Also I spent more time writing test cases than I expected, but the overall progress was satisfying. My mentors were very helpful and spent considerable time in managing the system and giving help and direction.
Useful links
- The original post that explain what I was intended to do at the beginning of summer can be found here.
- The midterm report that contain detailed explanation of the database backend can be found here.
- My fork of OpenSensorSearch at GitHub can be found here.
- The demo server where soon the described features can be tested is here.
Leave a Reply