
A closer look at the flexibility and scalability of a GeoNode deployment using Kubernetes and related Cloud concepts.
Mid-2020, we started a project with Fraym – a data science company working with manifold types of datasets to execute projects in countries that are undergoing substantial societal change places around the world where data has been traditionally hard to access. Spatial data, ranging from base data such as administrative boundaries to Earth Observation and satellite data, play an important role. The majority of the datasets will be reused in other project contexts, thus a solution for the management and discovery of spatial and non-spatial datasets is inevitable for the effective execution of data analysis processes. In close cooperation with the experts at Fraym, we developed a data platform based on the GeoNode software stack. The challenges here were a set of requirements:
- Flexibility: supporting the different dataset types such as raster, vector and tabular data
- Scalability: accommodating the large amount and variety of data (multiple terabytes, tens of thousands of more than 100k individual datasets)
- Availability: taking uptime into account (e.g. on-demand bootstrapping vs 24/7 operations)
- Processability: promoting processing functionality close to the data.
In this blogpost, we take a closer look at the first two aspects: flexibility and scalability. We look into the details of our deployment concept using Kubernetes on Amazon Web Services (AWS) and other related cloud concepts.
Enabling GeoNode for Kubernetes
GeoNode consists of a set of well-established Open Source solutions from the OSGeo community. GeoServer is the backbone for spatial datasets and interoperable web interfaces, PostGIS serves as the central data persistence unit, pycsw provides the search & discovery capabilities and a web application based on Django acts as the connecting component as well as the entry point for users of the platform.
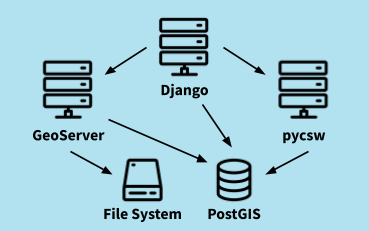
The starting point for the Kubernetes deployment was a set of Docker images provided by the GeoNode project in combination with docker-compose files. At the time of the project start, the latest version of GeoNode was 3.0. The first step was to migrate the docker-compose files to Kubernetes manifests. This included the definition of deployments, services, volumes and ingresses. Unfortunately, the deployment of this plain migration failed and we needed to do a thorough debugging. As a result, we needed a set of adjustments. The most important ones were:
- An init container for GeoServer: the OAuth configuration that enables the secure communication between Django and GeoServer had to be initialized using config file manipulation
- Inter-component dependencies (e.g., Django needs to wait for PostGIS) had to be migrated to an approach that works with Kubernetes
- Adjustment of bootstrapping steps (“fixtures”), e.g. the synchronization of administrative logins (“default passwords”) between Django and GeoServer
- Removal of “shared volumes” (as in docker-compose).
In combination with different config maps to provide the base configuration of Django and Geoserver, these adjustments formed the basis for the successful deployment of GeoNode in a Kubernetes cluster.
Making GeoNode “Cloud ready”
The next step was to evaluate the scalability of the as-is GeoNode installation. It soon became clear that GeoServer’s default configuration would not meet the project’s data requirements, particularly when taking storage capacity and pricing into account. In the standard installation, GeoServer stores raster data (e.g., GeoTiff) on the file system. In AWS, this would be a volume Kubernetes managed and is effectively an Elastic Block Storage (EBS). EBS is rather expensive and storing multiple terabytes is not an option. A solution based on Amazon S3 was inevitable. In addition, a single node GeoServer will most likely not be able to serve parallel requests while accessing the large amount of datasets. A cluster solution for GeoServer would provide a handy solution. Both adjustments required a customized GeoServer build. The latter was achieved by integrating the “JMS Cluster” community plugin and adding an ActiveMQ message broker to the deployment. The broker is used for the synchronization between the GeoServer cluster nodes.
We achieved S3 support by integrating the S3GeoTiff community plugin and a customized data ingestion process. During this phase, data ingestion via the UI is not of high importance, since dedicated scripts must carry out the ingestion of the large amount of existing datasets. We developed a Python module that a dedicated Django management command can trigger. The steps for ingesting GeoTiffs into Django are as follows:
- Identification of the relevant files (e.g., <filename>.tif) and corresponding metadata files (dublin core profile with <filename>.xml)
- Upload of the GeoTiff file to an S3 bucket on AWS
- Creation of a coverage datastore and a corresponding layer using the S3GeoTiff plugin via the GeoServer REST API
- Registration of the new layer in Django.
We designed the data ingestion Python module to easily support other data formats and potential custom ingestion processes (e.g., NetCDF) as well. It reuses the existing functionality of GeoNode whenever possible, thus integrating seamlessly with the overall system.
Wrap Up
In summary, we extended the default architecture of GeoNode with S3 support for raster data as well as cluster support for GeoServer. The figure below illustrates these enhancements.
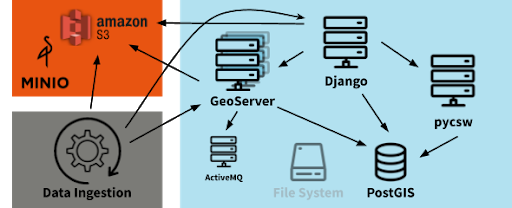
We built our development environment on a minikube installation. AWS S3 is not available here. Therefore, our team designed the data ingestion using S3 to additionally support other S3 implementations, such as min.io.
What’s next?
During the next phase of the project, we will focus on the data ingestion. Our team will evaluate the scalability and performance of the GeoNode stack thoroughly and apply custom measures when necessary. Simultaneously, we will set up a processing environment that leverages the concepts of the spatial data management platform. Stay tuned for more details about these developments in an upcoming blog post!
If you are interested in our work with GeoNode and Kubernetes, please get in touch with Matthes Rieke.
Leave a Reply