Introduction
The enviroCar App: Voice Command project aims to automate the enviroCar application’s actions via voice commands to provide a user-friendly experience. My goal is to add voice command features to the app as part of Google Summer of Code 2022. You can read my earlier blog, which provides an overview of this project. This blog post describes the intermediate results up to now. The project’s goals and their implementations have made significant progress.
Project Goals
Prepare the enviroCar App for voice command integration
The first goal for the project was to prepare the enviroCar App for voice command integration. I achieved this goal by creating software designs, which include a UML (Unified Modeling Language) class diagram, a component diagram, and a speech recognition pipeline.
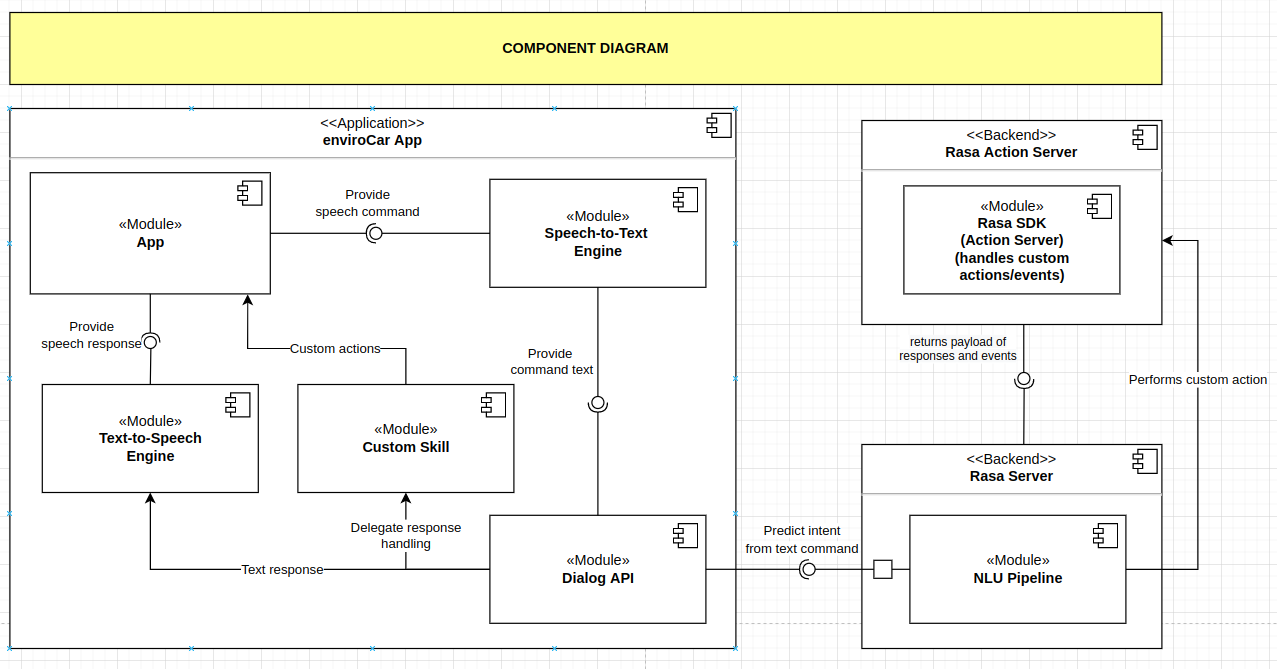
The component diagram assisted us in accurately illustrating the operation and behavior of all the required components (Fig. 1):
- enviroCar App is the application that handles UI, provides speech commands, and performs custom actions based on the response handled by the Dialog API class.
- Rasa Server is the main backend server that takes care of the NLU Pipeline and predicts the intent from the text passed from the app.
- Rasa Action server runs custom actions for the Rasa server. When the action server finishes running a custom action, it returns a payload of responses and events.
The Rasa server then returns the responses to the user and adds the events to the conversation tracker. The conversation tracker lets you access the bot’s memory in the custom actions. One can get information about past events and the current state of the conversation through its methods.
After getting a proper understanding of the design, I implemented the voice command functionality within a separate Gradle module which can be seen here. Then I integrated it into the existing enviroCar App module. Implementing the functionality within a separate module will let us build, test, and debug the voice command functionality independently from the main enviroCar App. It will encapsulate the feature into a separate module, which makes it reusable.
Trigger voice command and translate speech to plain text
As mentioned in my last blog post, we will use the AimyBox library throughout the project with the voice-trigger part by adding a prebuilt language model provided by vosk-api. While implementing, I noticed that the voice trigger was getting triggered by words other than the woke word (“enviroCar listen”). So we dropped the plan to use a model provided by vosk-api and now we are using the prebuilt CMU Pocketsphinx language model. Pocketsphinx provides many features that will contribute to our project, a few are listed below:
- Models are easy to use, adaptable, and powerful. It also has well-defined documentation.
- Models work offline and are lightweight, which can help reduce the load from the smartphone.
- Size of each model is as small as 10MB for English and 40MB for German.
- Support for several languages like US English, UK English, German, and the ability to build models for others.
I will work with the English language model and integrate a German model once proper testing is done. We will also use a phonetic dictionary and extend it for new words. A phonetic dictionary provides a mapping of vocabulary words to sequences of phonemes. One might look like this:
hello H EH L OW world W ER L D
I have added custom words to the dictionary to use it for voice trigger.
car K AA R hey HH EY envirocar EH N V AY R OW K AA R listen L IH S AH N ok OW K EY
The project’s primary task was to recognize and translate user speech into plain text. I had planned to add voice triggers similar to google assistance, which is triggered after saying ‘ok google’. For our project, we experimented with different wake words like “enviroCar listen”, “hey enviroCar” and “hey car”. After discussing it with my mentor, I chose the word “enviroCar Listen” because that was direct and on point. It was also giving the highest accuracy with the Pocketshpinx library used for voice trigger.
I integrated the Pocketsphinx library within the voice-command module. Along with that, I implemented GooglePlatformSpeechToText, which will recognize the user’s speech and translate it to plain text.
In addition to all the features, Pocketsphinx provides tutorials to achieve higher accuracy which can be part of possible future improvements.
- Adapting the default acoustic model
- Reasons to adapt an acoustic model rather than train new
- You need to improve accuracy
- You do not have enough data to train
- You do not have enough time
- You do not have enough experience
- Reasons to adapt an acoustic model rather than train new
- Tuning speech recognition accuracy
Integrating the feature in settings and giving visual feedback
Once the voice trigger implementation was ready, it was time to integrate the voice command feature in settings. The plan was to let users enable the voice-command feature from the app’s settings. I worked on creating this flow and implemented it in the app. These are the commits that show the flow implementation: Added feature in settings, updated voice command setting description, ask for microphone permission after enabling feature, and added a check for microphone permission in the main activity. The image below shows the enabling of the voice command feature.
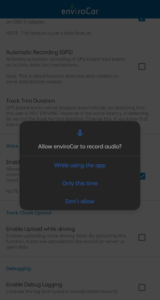
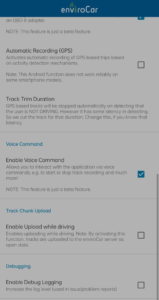
It’s important to give auditory and visual feedback whenever the voice command feature has been triggered. The audio feedback part will be handled by AimyBoy, which uses Google Text-to-Speech. For the visual feedback, I implemented a custom good-looking snack bar for voice trigger.
Here’s a screen recording showing the whole flow in the app:
Recognizing the user’s intent via NLP/NLU
After transforming the user’s speech to plain text, the third goal was to use natural language processing/ natural language understanding (NLP/NLU) to recognize the user’s intent and perform an appropriate action in the enviroCar App. For this purpose, we used Rasa Open Source for the NLP/NLU part and created a robust model to recognize the action. This goal was the most important to achieve as the NLU/NLP model will be the main driver of the application. The model created by Rasa will understand the intent and give a correct response to the application to perform actions. With that in mind, I started working on this by exploring Rasa functionalities and creating simple stories.
Stories are a type of training data used to train the assistant’s dialogue management model. They drive the training data in conversation.
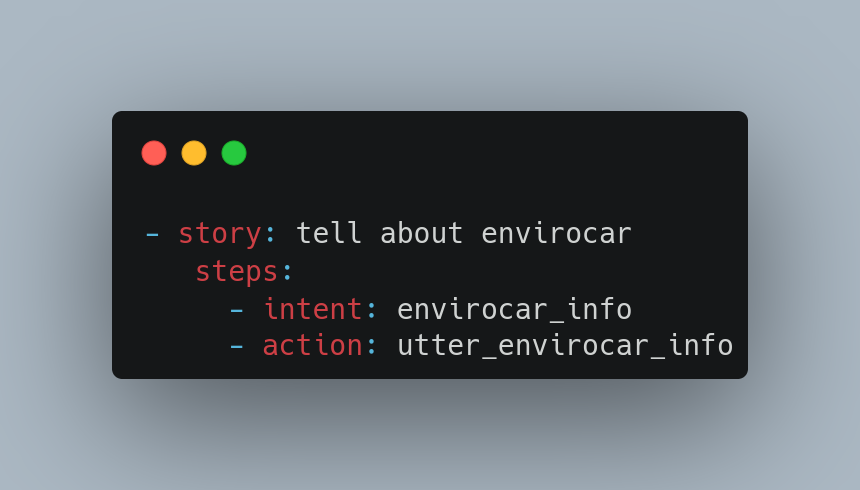
The snippet shows a story I created to describe the enviroCar App. This story will get triggered when an intent “envirocar_info” is triggered by a dedicated sentence. Then it will run the action “utter_envirocar_info”, which speaks about the enviroCar App.
Rasa provides various components that make up our NLU pipeline and work sequentially to process user input into a structured output. The starting point for a project would be deciding whether to load pre-trained models or not. If you’re starting from scratch, it’s often helpful to start with pre-trained word embeddings. Since we are creating a domain-specific bot, it’s always better to use supervised embedding instead of pre-trained.
For example, in general English, the word “recording” is closely related to “recording pictures/videos”, but very different from our use case “track”. In our domain, “recording” and “track” are closely related and we want our model to capture that.
Hence, we went with the default pipeline along with RegexEntityExtractor to train our model.
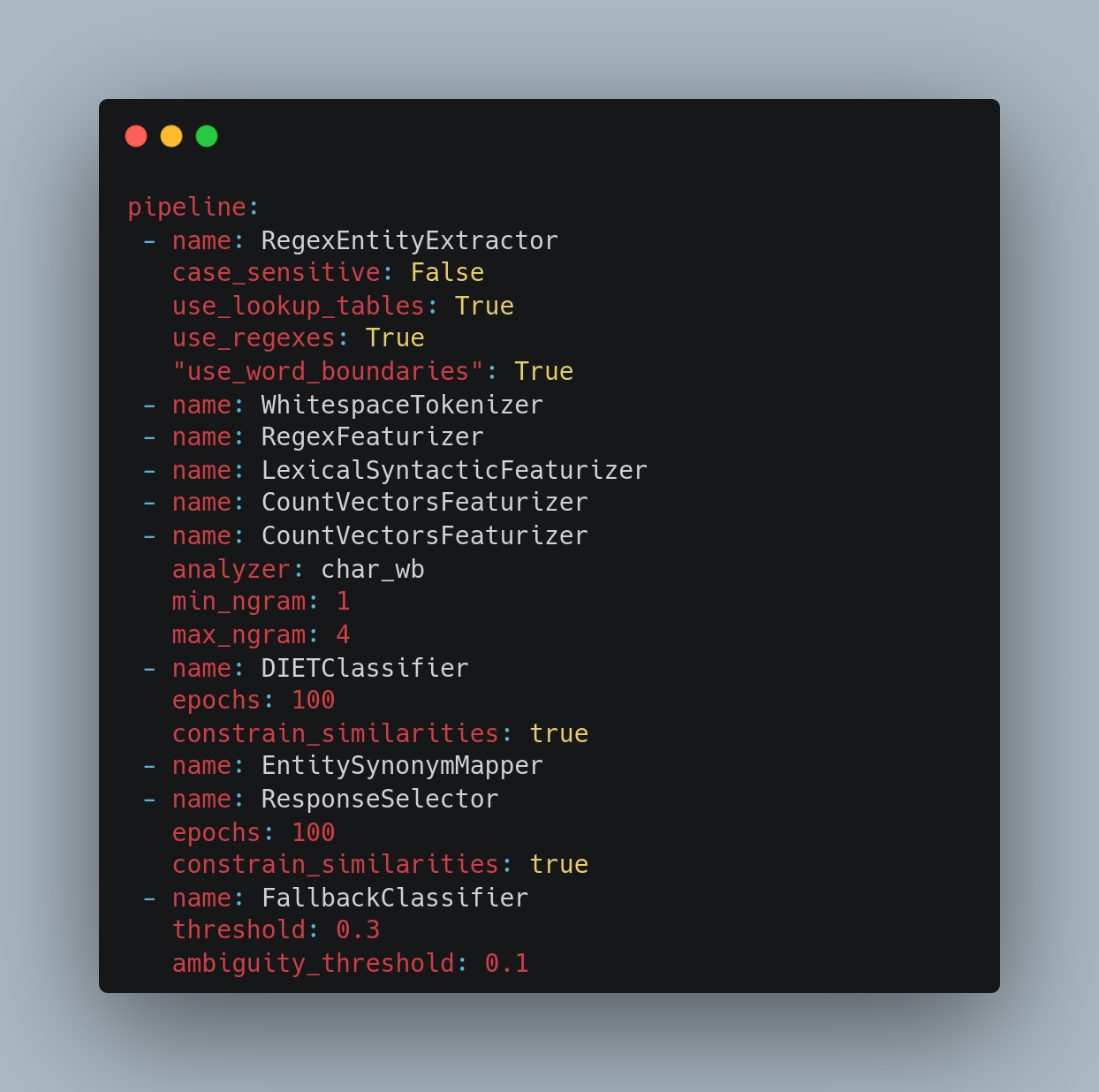
- RegexEntityExtractor extracts entities using the lookup tables and/or regexes defined in the training data. This can be helpful because there are various ways users can say “start recording”, eg. begin recording, launch recording, etc.
- Tokenizers split the text into tokens. WhitespaceTokenizer creates a token for every whitespace-separated character sequence.
- Featurizers create a vector representation of user messages, intents, and responses.
- DIETClassifier is used for intent classification and entity extraction
- EntitySynonymMapper maps synonymous entity values to the same value.
- ResponseSelector predicts a bot response from a set of candidate responses.
- FallbackClassifier classifies a message with the intent nlu_fallback if the NLU intent classification scores are ambiguous.
I implemented the training data for start and stop recording along with stories that can drive the training data in conversation.
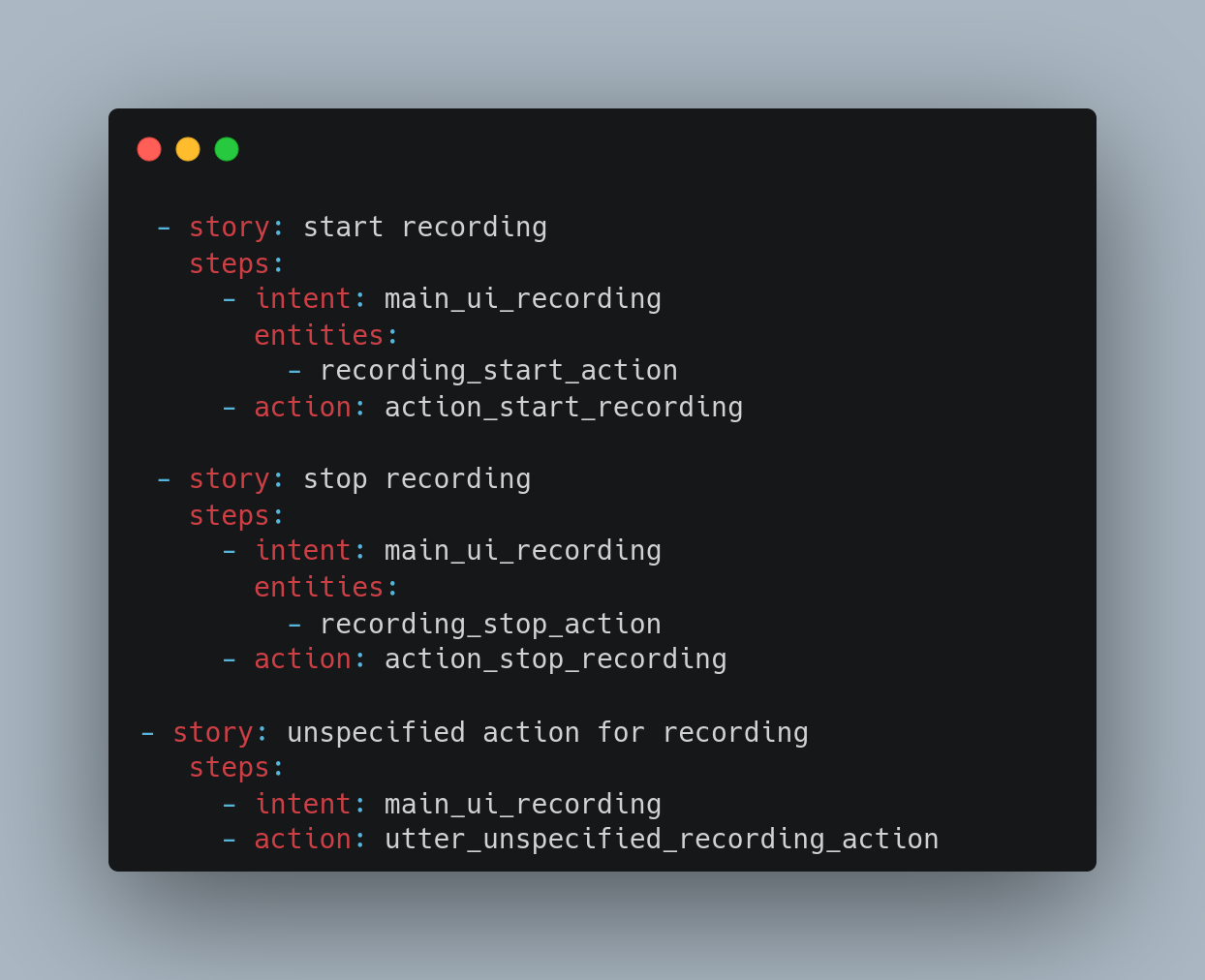
This will only detect a particular entity and respond with data to some extent. Before starting track recording, different prerequisites have to be checked. Rasa should evaluate these prerequisites and give the user an appropriate response, e.g. “Please, enable GPS”. To achieve this, we will develop a proper request and response model schema along with the stories and rules for fulfilling requirements.
Rasa provides Custom Actions to evaluate the prerequisites mentioned above. They can run any code we want, e.g. it can check the status of prerequisites to start recording for us.
I worked on this repository to maintain the code for the Rasa part of the project. It now has over 55 commits and I believe that we are on the correct path to achieve our third goal.
Action Points
I will continue to work on our goals, resolve the bugs and improve the existing features. This includes:
- Develop a request and response schema to check prerequisites for voice commands
- Implement start/stop recording command
- Create Rasa stories and rules for car selection
- Implement car selection command
- Run user tests
- Testing/ Bug fixing
Closing remarks
Till now, the GSoC journey has been going great. I’d say we’re headed in the correct direction as far as implementing and taking into account how crucial the voice command feature is in the app. I want to thank Sebastian, sir, my mentor, for looking over my code, and approaches and helping me with the implementation. It is a terrific learning experience to create something from scratch, design UML diagrams before implementing them, and see how the feature can be addressed using several techniques.
Leave a Reply