Introduction
The project aims to stabilize and enhance the enviroCar: Voice Command project to achieve better road safety and hands-free user experience using voice commands. As a part of Google Summer of Code 2023, my goal includes increasing the accuracy of wake word detection, stabilizing existing and adding new voice commands, creating CI/CD pipelines, and an overall increase in the user experience of the enviroCar app. You can read my earlier blog, which provides an overview of this project. This blog highlights the progress made so far and gives an insight into future plans.
Project Goals
1. Improving the accuracy of wake word detection:
As the last blog post mentioned, wake word detection in the enviroCar Voice Command project was implemented with AimyBox library and PocketSphinx speech kit as part of the GSoC 2022. The problem was the low accuracy of this implementation.
Wake word detection accuracy here is a direct outcome of the PocketSphinx Model under the hood. While researching methods for improving model accuracy, I discovered a major concern, viz the discontinued maintenance of PocketSphinx models. The English model on the official CMU SourceForge repository was last updated ~ 7 years ago and the German ~ 6 years, which is not suitable for the project. While choosing an alternative speech kit seems to be a good solution, there are plenty of reasons for sticking with AimyBox. It provides an end-to-end framework for speech recognition and intent classification through Rasa. Furthermore, it features custom skills for performing operations on the client’s device. AimyBox provides support for the following wake word detection speech kits:
- Kaldi
- PocketSphinx
- Snowboy (Discontinued)
While exploring these other alternatives I considered the following factors:
- Model Accuracy:
Model accuracy is of utmost importance. The model should be able to detect the wake word in different accents, tones, and pronunciations. This directly affects the user experience and the usability of this feature.
- Model Adaptation Pipelines:
The model should have a dedicated and well-documented model adaptation pipeline. Model adaptation is essentially a process of updating the model with new words and adjusting the probability of a few words specific to our requirements. This is crucial for future changes and enhancements.
- Future Model Updates:
One of the reasons for moving away from PocketSphinx is non-updating models. Model updates improve the model performance and also add support for newer words.
- Active Community/ Developers:
It ensures regular model updates, continued community support, and new features.
Considering these factors, Kaldi seemed to be outperforming the others. Kaldi uses Vosk models whose accuracies provide an edge over PocketSphinx. They have more frequent model updates, a wider library of models, and most importantly better model updation/ adaptation pipelines. Additionally, while CMU PocketSphinx dictionary contains 124k words, Vosk contains ~400k word definitions.
One of the concerning reasons for low accuracy is the absence of the word “enviroCar” from the model vocabulary. Neither of the models detect “enviroCar” as a word and so as a breakdown “enviro” and “car” works for some, including the Vosk models.
For adding “enviroCar” as a word and improving the accuracies of the Vosk models, we have to perform a process of Model Adaptation. Model Adaptation is essentially an activity that enables adding new words to the model as well as providing an ability to recognize some specific words better than others.
Adapting the Vosk model
Our primary goal with model adaptation remains the addition of “envirocar” and better detection accuracy of “enviroCar listen” while also giving us the flexibility to add new words in the future.
Vosk features three levels of adaptation:
- Dictionary Adaptation:
Performed for adjusting the relative probability of a few words. The provided words should be present in the model dictionary so that no new words can be added.<
- Language Model Adaptation:
>Performed for adding new words to the model. It involves phoneme generation on the basis of which the new word is added to the model dictionary. - Acoustic Model Adaptation:
Performed for improving the model voice recognition performance. It involves voice data of at least 1 hour for adaptation.
While Acoustic Model Adaptation requires custom voice data of at least 1 hour, we don’t necessarily need to perform this just for adding new words. The other two adaptations are enough for adding new words.
As a prerequisite to the process, we need a good set of phonemes for our word. Vosk recommends using g2p tools like Phonetisaurus for phoneme prediction. A Phonetisaurus flow to generate phonemes is represented below:
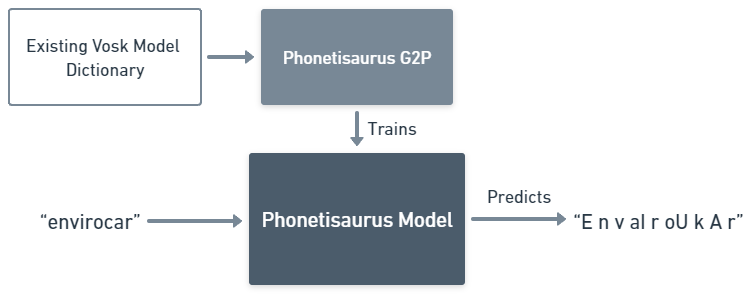
With this, we get a high-quality phoneme for “envirocar”:
envirocar E n v aI r oU k A r
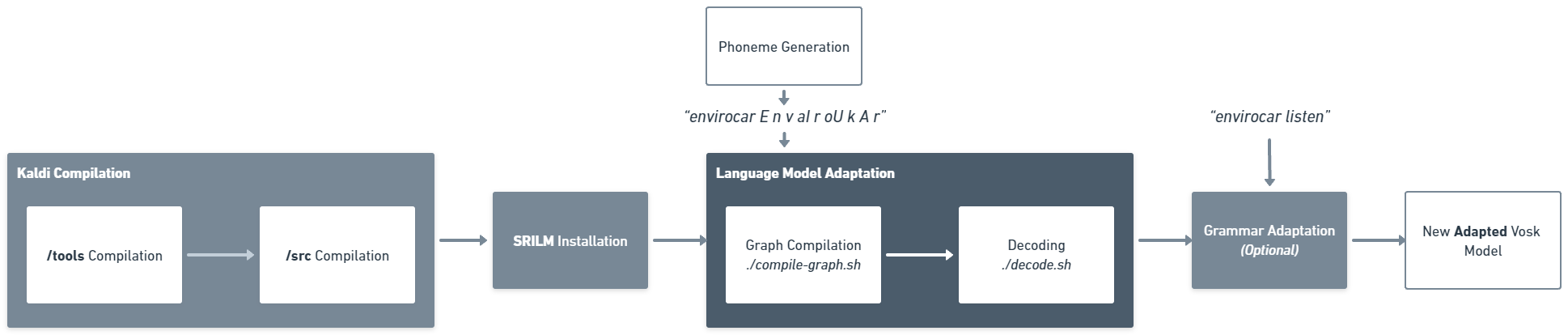
The entire process of language model adaptation is extensive if not done correctly. One might get trapped in installing dependencies manually if the shell scripts don’t work. I was able to pull it off on an Ubuntu 22.04 and will recommend the same. I have documented the entire process in my complete guide on how to adapt a Vosk model.
Briefly stated, it involves the following steps:
- Kaldi Compilation
- SRILM Installation
- Phoneme Generation
- Language Model Graph Compilation
- Language Model Decoding
- Grammar Adaptation (Optional)
For testing the new custom model, I generated ~20 German English TTS (Text-to-Speech) with the content “enviroCar listen is the trigger”.
Check out the results in my video.
2. Developing CI/CD pipeline for enviroCar Rasa bot:
The goal of this task is to develop a pipeline that will automate the manual processes of the Rasa bot, as well as streamline testing of new changes. It should also generate a report of the effects it has on the accuracy of the Rasa NLU/ NLP classification as stated in the earlier blog.
A CI Testing pipeline for the envirocar-rasa-bot is now implemented (#7) and tested on the repository. This GitHub Action workflow is based on a custom implementation of the official rasa-train-test-gha GitHub Action.
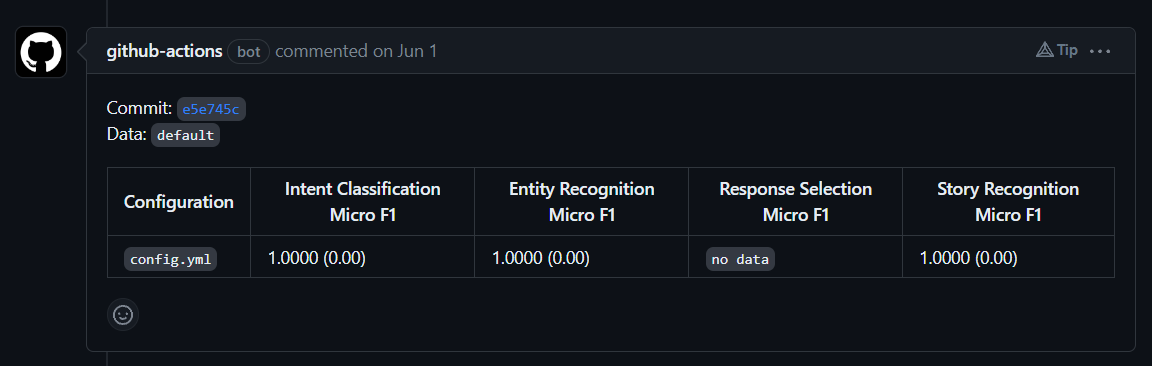
The workflow is triggered by pull requests. It provides a report on the effect of the changes committed in a pull request and valuable insights on whether the committed changes improve or degrade the accuracy of the bot. The report is published as a comment on the same pull request.
The pipeline is significant and will serve in providing valuable insights into upcoming pull requests specific to new voice command additions in the coming days. It also enables a new use case for rasa test stories.
Action Points
1. Stabilizing the bot
While there are some known issues and PRs that are currently open (#980, #985, #987, there is also a compulsive need for a complete review of the Voice Command branch, which is underway. While most of the architecture is well-designed and implemented, there are still parts that can be improved for a more robust system design and better code quality that will also help in improving code readability.
2. Expanding voice command flows further
The goal is to prioritize voice commands that are highly useful for the user while deprioritizing those that offer little value to their overall experience. One important point worth considering is not every action on the enviroCar app is performed while driving. The usability of the voice commands should enhance the driving experience and hence a categorization takes into account such factors.
For example, Tracking/Recording screen voice commands can be categorized as useful as they enhance the user experience. The user doesn’t have to take their eyes off the road to perform actions such as Start/Stop tracking, Data inquiry, etc giving a hands-free user experience or making the app accident free.
3. Writing tests
The final task involves testing out the implemented code and actively scanning for any newly introduced bugs through the code. As mentioned in the last blog, goals include the development of functional and performance tests for the Android app and test stories for the Rasa backend. As the CI pipeline for the envirocar-rasa-bot is already active, creating test stories adds more value to the NLP bot and ensures that any new change does not degrade the accuracy and functionality of the bot.
Closing Remarks
In conclusion, the midway point of the Google Summer of Code 2023 has arrived. It has been a really amazing journey till now. I am exposed to new challenges every day and get to evaluate different perspectives and solutions to them. It has been a really enticing experience. I got to learn new technologies and design concepts and it has not only broadened my horizons, but also fostered a sense of camaraderie and belonging within the organization and the open-source community. I am happy that the project has witnessed significant strides and achieved key milestones. From conceptualization to implementation, we have had great momentum. Looking ahead, with the second half of the program starting, I would strive to increase the momentum further and commit to driving the project toward a successful completion.
Leave a Reply