As part of my external semester at 52°North, I am involved in a project in which we develop a web crawling solution for multilingual discovery of environmental data sets.
Context
European Centre for Medium-Range Weather Forecasts (ECMWF), an European transnational weather forecasting and research center, hosts a “Summer of Weather Code”. For the first time this year and in the spirit of Google Summer of Code, the UK based organization published calls for proposals on topics that may need improvements. “Visualizing Forecast Verification”, “Web Crawler for hydrological Data” or “NetCDF managed as a filesystem” were among the 10 proposed topics. Accepted proposals were to be implemented between May and August.
I had decided earlier that I would do my external semester for my master studies at 52°North during that time and was asked if I would participate in a small team in this challenge. The “Webcrawler for hydrological data” proposal was of most interest to us all, as it would address issues encountered previously in projects at 52°North. In addition, it was an interesting technical challenge. The team submitted a proposal, and on April 30th we were notified that we were shortlisted to implement a solution.
Motivation
Building a global predictive weather forecasting model depends on lots of data, and while some of it is available and easily discoverable through data catalogs, most of it is not. At ECMWF, a big task is to discover new data sets from around the world in an effort to improve the models. Especially in countries of the global south data availability and discoverability is low. Specifically, real-time data on hydrological phenomena, such as stream flow, is of interest to validate previous predictions.
The current approach at ECMWF is to manually search the web with common search engines, using keywords in various languages, and reviewing the resulting pages by hand. In particular the required translation step makes this a lengthy task.
The Solution
In an effort to automate as much as possible of this task, we proposed a service that…
- translates keywords into several languages
- indexes a subset of the web, seeded by a Google search with the translated keywords
- scores the resulting pages in regards to the question “does contain/link to data?”
- extracts metadata about the data from the pages (where possible).
This functionality is wrapped in a web UI with a result viewer and crawl management interface.
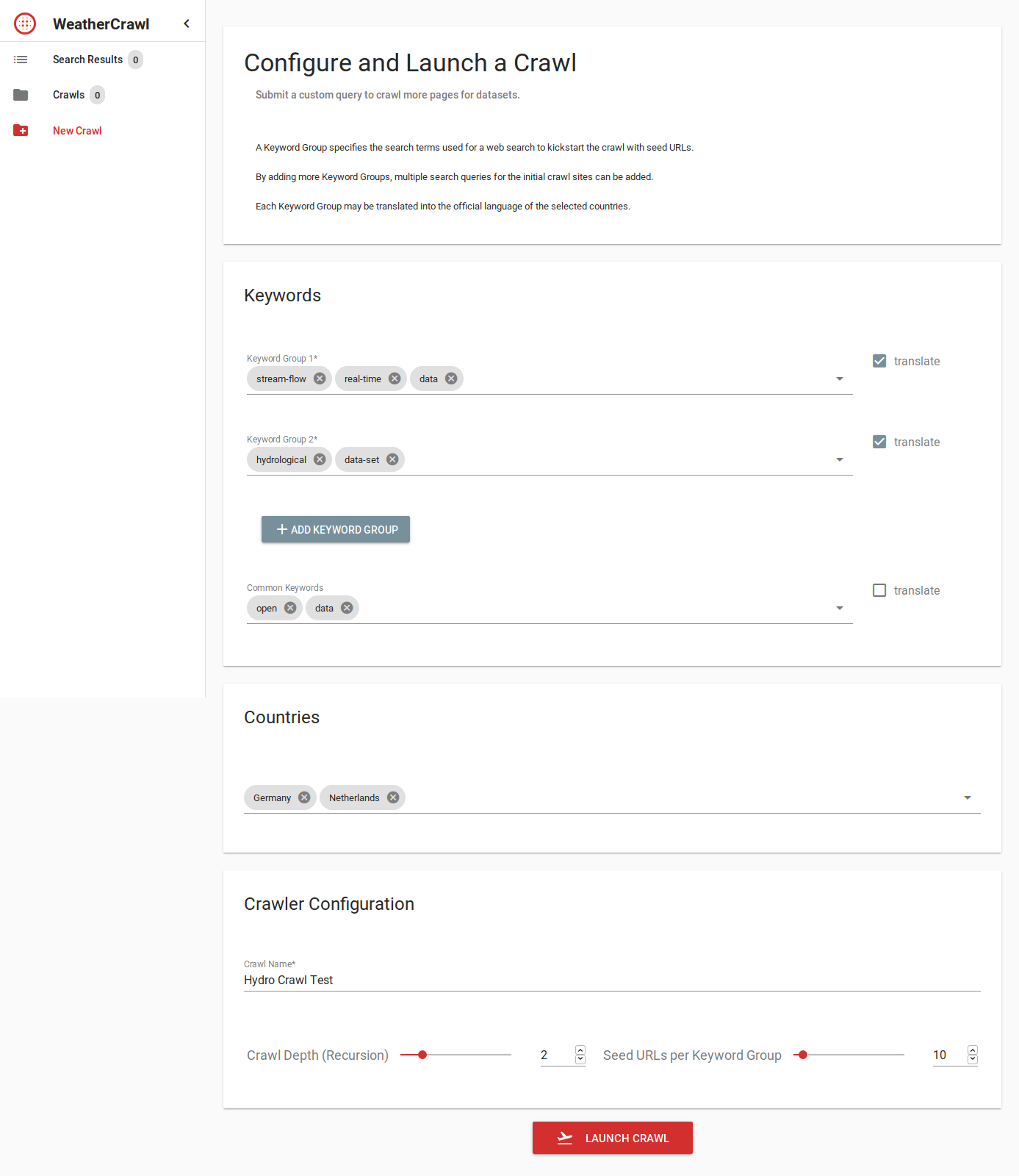
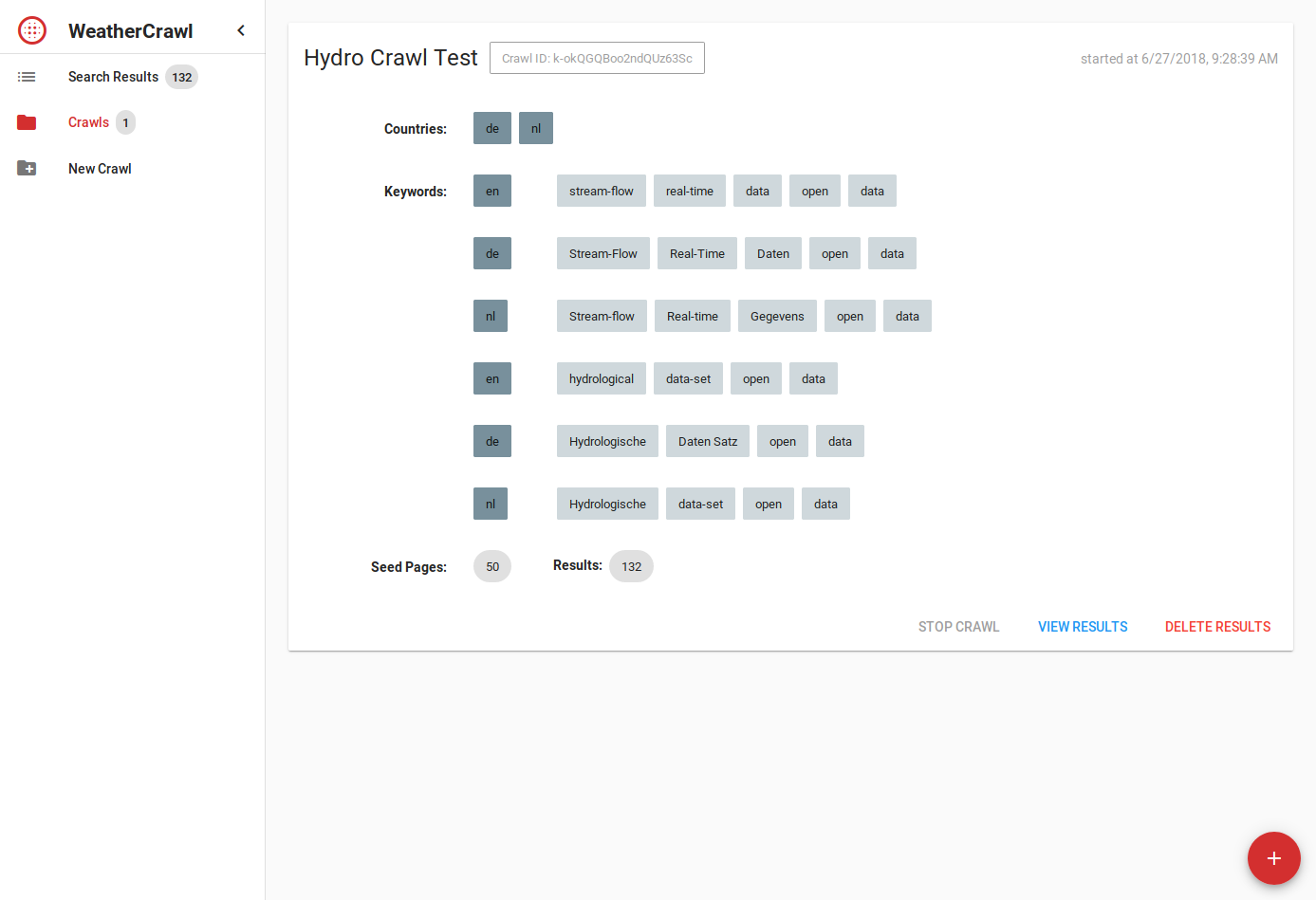
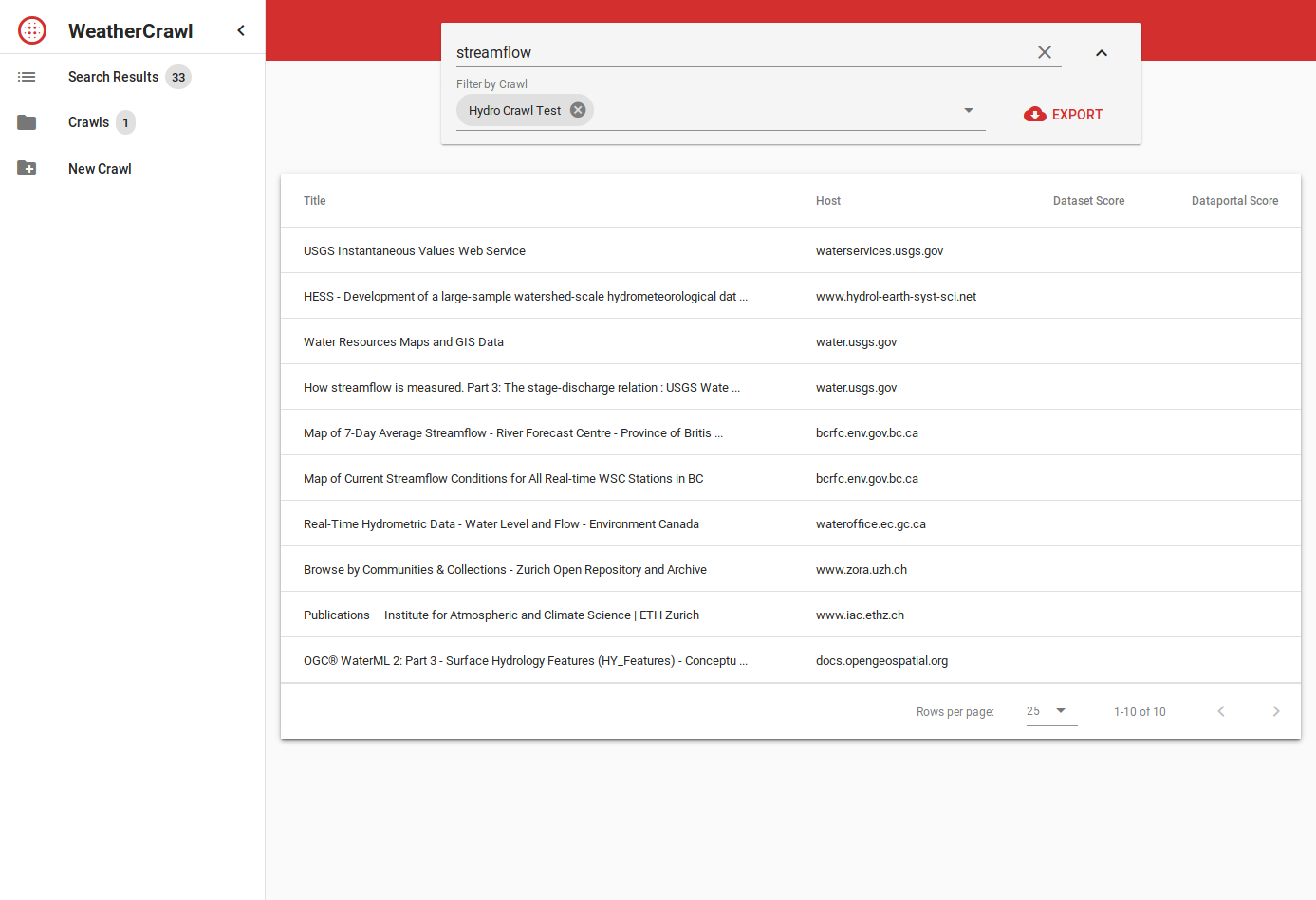
While tasks 1 and 2 are quite straight forward, tasks 3 and 4 are unknown territory and we need to evaluate different methods for content analysis. Both tasks require extraction of page content and subsequent analysis and rating of the extracted data.
We are first testing matching of certain HTML structures with XPath, or fuzzy-matching the document text with a set of keywords. First evaluations of results show, that these rather simple approaches are simple to implement but have limitations:
- matching only known document structures (which is especially problematic when targeting foreign languages)
- not considering the context of matched content
- manual, error-prone curation of queries.
This leads to both many missed hints on data (false negatives) and matches for unrelated content (false positives).
A solution to this is to use natural language processing (NLP) algorithms to consider the context of words (such as Word2vec), and machine learning to generalize from a known set of training data to the unknown set of “web pages linking to data sets”.
The Process
At this point an integrated setup of crawler, indexing, and web UI has been completed. We now focus on prototyping and evaluation of approaches for the content analysis module. In spite of it being a difficult problem, there’s a lot to learn about NLP and machine learning and I am looking forward to the results we can achieve with these advanced approaches.
The ECMWF team of mentors is both really helpful and open to the results, as any improvement to the situation is considered a success.
I am currently doing the implementation, with helpful advice from 52°North staff. Development is done completely in the open on GitHub, so if you are interested in technical details and design decisions, the project wiki is a good place to start!
Leave a Reply