Implementing the Location Privacy Toolkit in the enviroCar App
Introduction
This blog is about the GSoC 2023 project I will work on this summer. It will contain the problem statement, an initial observation of the solution, and my approach toward the problem.
Caching for Sensor Web REST-API
There are only two hard things in Computer Science: cache invalidation and naming things.
Phil Karlton
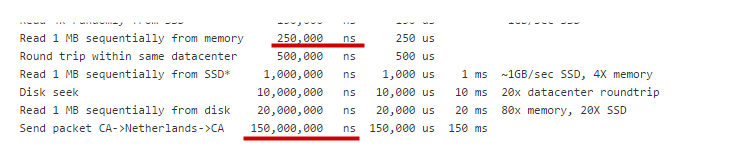
Caching is a common technique to improve the response time of a data source. A cache is a temporary storage for a most often acquired data. Caching is widely used in a proxying software such as Squid. The caching of network responses can provide a huge improvement to the response time. The latency of a network resource is much more greater than of a memory or a disk resource [Fig.1]. That’s why the caching is a “must-have” feature of network proxies.
Terrain Model Generation and Analysis
My name is Adhitya Kamakshidasan and I recently graduated from Visvesvaraya National Institute of Technology, Nagpur, India. I will be working on the Google Summer of Code 2016 project “Terrain Model Generation and Analysis” under the able guidance of Professor Dr. Benno Schmidt (Hochschule Bochum) and Christian Danowski (52°North).more >